 Получите свидетельство
Получите свидетельство Вход
Вход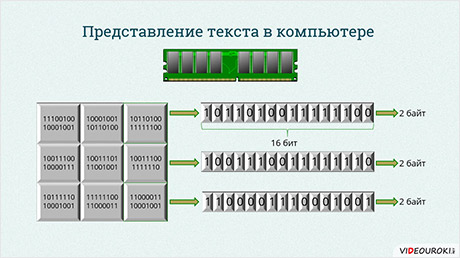



Вопросы занятия:
· таблица кодировки;
· использование таблицы кодировок;
· информационный объём текста.
Компьютер может работать с пятью видами информации:

Одним из самых массовых приложений ЭВМ является работа с текстами.
Имея компьютер, можно создавать тексты, не тратя на это много времени и бумагу. Носителем текста становится память компьютера. Текст на внешних носителях сохраняется в виде файла.
Как вы уже знаете, вся информация, независимо от того, какая она графическая, видео или звуковая, представляется в компьютере с помощью чисел, это всего два символа двоичного кода, 0 и 1, которые легко перевести в сигналы.
Прежде всего, вспомним о байтовом принципе организации памяти компьютера.

Как вы помните, каждая клетка обозначает бит памяти. Восемь подряд идущих битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. По этим адресам процессор обращается к данным, считывает их или записывает в память.

Схема представления текста в памяти компьютера очень проста. Каждая буква алфавита, цифра, знак препинания или любой другой символ необходимый для записи текста обозначается определённым двоичным кодом, длина которого фиксирована.

Например, в системах кодировки Windows – 1251 и KОИ-8 каждый символ заменяется на восьмиразрядное целое положительное двоичное число, оно хранится в одном байте памяти. Это число является порядковым номером символа в кодовой таблице.

Мы уже говорили о том, что разрядность ячейки памяти i и количество различных целых положительных чисел, которые можно записать в эту ячейку n связаны соотношением:

Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций, то есть 28 = 256.
С помощью 256 кодовых комбинаций можно закодировать все символы двух алфавитов (английского и русского) и все остальные дополнительные символы, расположенные на клавиатуре компьютера — цифры и знаки арифметических операций, знаки препинания и скобки и так далее, а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, переход на новую строку, пробел и другие).
Рассмотрим пример.
Мощность алфавита равна 256 символов. Сколько Килобайт памяти потребуется для сохранения 160 страниц текста, содержащего в среднем 192 символа на каждой странице?

В современном мире около 6700 живых языков и около 25 алфавитов.
8-разрядной кодировки хватает, для того чтобы можно было одновременно пользоваться не более чем двумя языками. Для того чтобы на компьютере можно было устанавливать больше языков был разработан новый стандарт кодирования символов, получивший название Юникод.
Юнико́д или Унико́д (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
Он является результатом сотрудничества Международной организации по стандартизации (ISO) с ведущими производителями компьютеров и программного обеспечения.
Этот стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода». С помощью этого стандарта можно закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
В Юникод каждый символ кодируется 16-битовым двоичным кодом, то есть два байта на символ. В данном случае можно закодировать 216 = 65536 различных символов.

Однако в последнее время объединение Unicode приступило к кодированию письменности мёртвых языков и в этом случае 16-битового кодирования уже недостаточно. Поэтому Unicode приступил к освоению новых кодов.
Иногда, работая с электронной почтой, программа может запросить нас воспользоваться кодировкой Unicode для пересылаемых сообщений. В таком случае можно избавиться от проблемы несоответствия кодировок, по которой иногда не удаётся прочесть русский текст.
Текстовый документ, который хранится в памяти компьютера, состоит из кодов символьного алфавита, кодов управления форматами текста. Также текстовые процессоры, например, Microsoft Word позволяют включать и редактировать такие объекты как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и так далее. Все это также представляется в виде последовательности байтовых кодов.
Вам известно, что информационный объём сообщения I равен произведению количества символов К в сообщении умноженному на информационный вес символа алфавита i:

В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 бит или 1 байт — если используется восьмиразрядная кодировка;
• 16 бит или 2 байта — если используется шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и так далее), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Рассмотрим пример.
Информационный объем текста, набранного на компьютере с использованием кодировки UNICODE равен 4 Килобайта. Определить количество символов в тексте.

Как мы уже говорили бывают случаи, когда, работая с текстом, программа может запросить воспользоваться другой кодировкой, например, текст в восьмибитном коде Windows перекодировать в кодировку Unicode. Давайте выясним, что произойдёт с информационным объёмом текста.

Итак, рассмотрим такой пример.
Информационное сообщение на русском языке, первоначально записанное в 8-битной кодировке Windows, было перекодировано в 16-битную кодировку Unicode. В результате информационный объём сообщения стал равен 2 Мегабайта. Нужно найти количество символов в сообщении.

Итоги урока.
Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц.
Существуют 8-разрядные таблицы кодировки – это ASCII, КОИ-8 и другие. А также 16-разрядная кодовая таблица Юникод.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 бит (1 байт) — если используется 8-разрядная кодировка;
• 16 бит (2 байта) — если используется 16-разрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов и производных единиц, необходимых для записи фрагмента оговорённым способом кодирования.

 9219
9219

