 Получите свидетельство
Получите свидетельство Вход
Вход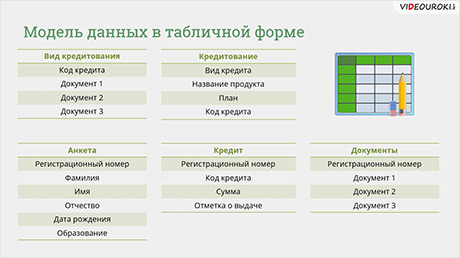



На данном уроке мы с вами научимся создавать структуру базы данных в виде таблиц, узнаем, какие отношения и связи бывают между таблицами, построим схему данных и многое другое.

Чтобы узнать, как правильно проектировать многотабличную базу данных, мы рассмотрим этот процесс на примере. Для этого нам необходимо вернуться к примеру моделирования работы кредитного отдела банка.
![]()
Для начала вспомним модель данных, которая состояла из трёх взаимосвязанных таблиц. Она выглядит следующим образом.

Данные таблицы представляют собой модель данных в реляционной СУБД. Но для удобной работы с базой данных, необходимо соблюдать некоторые требования.
Одно и главное из них – это отсутствие избыточности данных. Это говорит о том, что нужно избегать лишних данных при построении базы данных, так как это приводит к лишнему расходу памяти. При выполнении этого требования можно сократить не только потребность в памяти компьютера, но и время поиска и обработки данных.

Видимый недостаток наших таблиц в том, что многократно повторяются значения полей в разных записях. Например, Вид кредита будет повторяться в 50 записях для 50 кредиторов, которые подали документы на кредит. Для удобства можно в таблице «Кредитование населения с учётом плана» добавить поле «Код кредита», а в таблице «Вид кредитования» поле «Вид кредита» заменить на поле «Код кредита». Таким образом, вид кредита будет записан только единожды, а в анкетах кредиторов будет стоять код. Аналогично изменим поле «Вид кредита» на поле «Код кредита» в таблице «Кредиторы». А также изменим название таблицы «кредитование населения с учётом плана» на «Кредитование».
После изменения получим следующее.

Далее следует обратить внимание на таблицу «кредиторы». Она слишком большая и не удобная для работы. Можно разбить её на несколько таблиц поменьше. Получим следующее:

Такие таблицы более удобны.
В таблице «Анкета» содержатся данные о кредиторе. В таблице «Кредит» содержатся данные о виде кредита, сумме и отметке выдачи. А в таблице «Документы» содержится информация о поданных документах на кредит.
У нас получилось пять таблиц. Давайте представим их в строчном виде. Подчёркнутые поля будут обозначать ключевое поле.

Для представления системы, все наши пять таблиц должны быть связаны между собой.
Если внимательно посмотреть на наши таблицы в строчном виде, то мы можем увидеть связи. Например, две первые таблицы имеют общее поле «Код кредита», а третья, четвёртая и пятая – регистрационный номер.
Связи помогают определить соответствия между любыми данными в этих таблицах, например, между фамилией кредитора и документами, которые он подал для кредитования. Благодаря этим связям можно получить ответы на запросы, которые требуют поиска информации в нескольких таблицах одновременно.
Следующее, с чем мы должны с вами познакомиться – это схема базы данных. Она создаётся для указания связей между таблицами. В схеме отображается наличие и типы связей между таблицами.
Если отобразить связи для нашей базы данных, то мы получим следующее:

Существует такие типы связей: «один к одному» и «один ко многим».
Чтобы показать связь «один ко многим», добавим ещё одну таблицу «Перечень документов», которая будет состоять из двух полей: «Номер документа» и «Документ». В поле «Документ» будут перечислены все возможные документы для всех видов кредита.
Связь «один к одному» обозначается двунаправленной стрелкой, а связь «один ко многим» – одинарной стрелкой в одну сторону и двойной в другую. При связи «один к одному» с одной записью в таблице связана одна запись в другой таблице. Например, одна запись о кредиторе связана с одной записью о поданных им документах.
Связь «один ко многим» означает, что одна запись в одной таблице связана с несколькими записями в другой. Например, с одним видом кредита связано несколько видов документов.
Что же такое целостность данных?
Целостность данных – это свойство базы данных, которое обеспечивается поддерживанием организации связи между таблицами базы данных, которое осуществляет СУБД.

Система не позволит, чтобы одноименные поля в разных связанных между собой таблицах имели разные значения. Поэтому система автоматически контролирует ввод данных.
В связанных таблицах можно устанавливать режим каскадной замены. Это говорит о том, что при изменении значения поля в одной таблице, по которому установлена связь, будут автоматически изменены значения одноименных полей в других таблицах.
Если же установить режим каскадного удаления, то достаточно удалить запись из одной таблицы, чтобы связанные записи исчезли изо всех остальных таблиц.

На данном этапе проектирование базы данных подошло к концу.
Подведём итоги нашего урока.
Главное требование для удобной работы с базой данных – это отсутствие избыточности данных.
· Связи помогают определить соответствия между любыми данными в этих таблицах.
· Схема базы данных создаётся для указания связей между таблицами.
· Типы связей бывают следующих видов: «один к одному» и «один ко многим».

 0
0 9591
9591

