 Получите свидетельство
Получите свидетельство Вход
Вход



Курс: 2
Дисциплина: «Математика»
Подготовила: преподаватель высшей категории Бирюкова Людмила Николаевна
Ставрополь 2018 год

Термин статистика происходит от латинского слова «status».
В Средние века это означало политическое состояние государства.
В науку этот термин ввёл немецкий учёный Годфрид Ахенваль.
Зарождение статистики, как науки, следует отнести ко второй половине XVΙΙ века.

В настоящее время термин «Статистика» употребляется в четырёх значениях:
1. Комплекс дисциплин , обладающих определённой спецификой и изучающих количественную сторону массовых явлений и процессов в их неразрывной связи с их качественным содержанием – учебный предмет в ВУЗ-ах и СУЗ-ах;
2 . Отрасль практической деятельности по сбору, обработке, анализу и публикации массовых цифровых данных о самых различных явлениях и процессах общественной жизни;
3 . Совокупность цифровых сведений , характеризующих состояние массовых явлений и процессов общественной жизни;
4. Статистические методы , применяемые для изучения социально-экономических явлений и процессов.

Статистика как наука имеет свой предмет исследования. Она исследует не отдельные факты, а массовые социально-экономические явления и процессы, выступающие как множество отдельных факторов, обладающих как индивидуальными, так и общими признаками.

Статистические данные – это сведения о числе объектов какого - либо множества, обладающих некоторым признаком.
Пример.
Сведения о количестве отличников в каждом учебном заведении;
сведения о числе разводов на число вступивших в брак;
сведения о количестве новорожденных и др.

На основании статистических данных можно делать научно – обоснованные выводы. Для этого статистические данные определенным образом должны быть систематизированы и обработаны.
Математическая статистика изучает математические методы систематизации, обработки и использования статистических данных для научных и производственных нужд.

Основной метод обработки данных – выборочный
Явления и процессы в жизни общества изучаются статистикой посредством статистических показателей , представляющих собой обобщённую числовую характеристику какого-либо явления в единстве с качественной стороной в условиях конкретного места и времени.

Различают следующие статистические показатели:
учётно-оценочные , которые в зависимости от специфики изучаемого явления могут отображать или объёмы их распространенности в пространстве или достигнутые на определённые моменты (даты) уровни развития. (Например: численность населения в России на начало 2002 года составила 146,3 млн. чел.);
аналитические показатели , применяются для анализа статистической информации и характеризуют особенности развития изучаемого явления: типичность признака, соотношение его отдельных частей, меру распространения в пространстве, скорость развития во времени и т.д. В качестве аналитических показателей в статистике применяются относительные и средние величины, показатели вариации и динамики, тесноты связи и др.

Различают следующие статистические показатели:
Одной из важных категорий статистической науки, тесно связанной с показателями, является понятие признака, под которым понимается характерное свойство изучаемого явления, отличающее его от других явлений.
Признаки бывают:
атрибутивные , выраженные смысловыми понятиями (пол – мужской, женский; магазин – продовольственный, промтоварный, хозяйственный);
количественные – признаки, выраженные числовыми значениями (возраст человека, стаж работы, размер заработной платы и т.д.);
варьирующие , принимающие различные значения у отдельных единиц изучаемого явления (товарооборот, валовой сбор и т.д.).

Статистика рассматривает статистические совокупности.
Статистическая совокупность представляет собой множество единиц изучаемого явления, объединённых в соответствии с задачей исследования единой качественной стороной, т. е.
признаками
Целью изучения статистических совокупностей является выявление закономерностей.
Закономерность – это то общее что определяет единство и однородность совокупности.
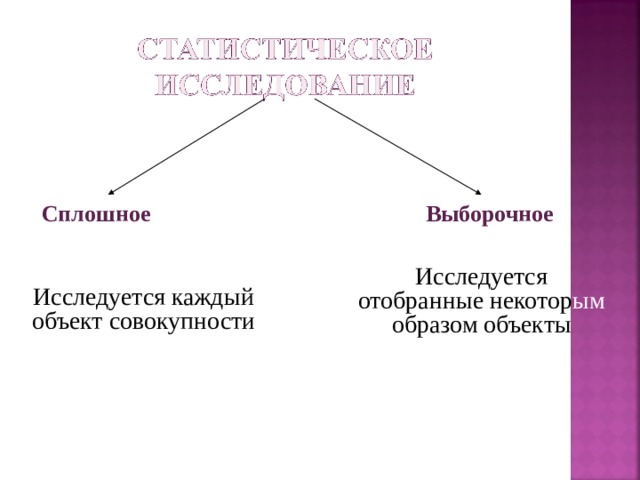
Сплошное Выборочное
Исследуется отобранные некотор ым образом объекты
Исследуется каждый объект совокупности

Генеральная совокупность – совокупность всех исследуемых объектов
Выборочная совокупность (выборка) – совокупность случайно отобранных объектов
Случайный отбор – это такой отбор, при котором все объекты генеральной совокупности имеют одинаковую вероятность попасть в выборку
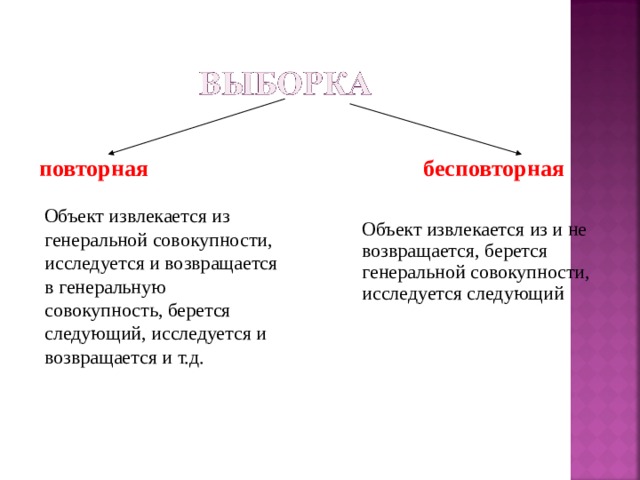
повторная бесповторная
Объект извлекается из генеральной совокупности, исследуется и возвращается в генеральную совокупность, берется следующий, исследуется и возвращается и т.д.
Объект извлекается из и не возвращается, берется генеральной совокупности, исследуется следующий

Объём выборки – это число равное количеству объектов генеральной или выборочной совокупности.
Пример.
Из 10000 изделий для контроля отобрали 100 изделий.
Объем генеральной совокупности равен 10000, объем выборки – 100.

Математическая статистика занимается вопросом : можно ли установив свойство выборки , считать, что оно присуще всей генеральной совокупности.Для этого выборка должна быть достаточно представительной , т.е. достаточно полно отража ть изучаемое свойство объектов.
Поэтому отбор объектов в выборку осуществляется случайно , а изучаемому свойству должна быть присуща статистическая устойчивость : при многократном повторении исследования наблюдаемые события повторяются достаточно часто (статистическая устойчивость частот)

Для статистической обработки результаты исследования объектов, составляющих выборку, представляют в виде числовой выборки (последовательности чисел или числового ряда)
Показатели описательной статистики можно разбить на несколько
групп:
- показатели положения, описывающие положение экспериментальных
данных на числовой оси. Примеры таких данных – максимальный и минимальный элементы выборки , среднее значение , медиана , мода и др.;

- показатели разброса, описывающие степень разброса данных относительно центральной тенденции. К ним относятся: выборочная дисперсия, разность между минимальным и максимальным элементами ( размах, интервал выборки ) и др.;
- показатели асимметрии: положение медианы относительно среднего и др.;
- графические представления результатов – гистограмма, частотная диаграмма и др.

Разность между наибольшим значением числовой выборки и наименьшим называется размахом выборки

Рассмотрим числовую выборку объема n , полученную при исследовании некоторой генеральной совокупности
Значение x 1 встречается в выборке n 1 раз
x 2 встречается n 2 раза
…… .
x n встречается n n раз
Числа называются частотами значений
Отношения частот к объему выборки
называются относительными частотами значений

Если составлена таблица в первой строке значения выборки, а во второй частоты значений, то она задает статистический ряд , если второй строке относительные частоты значений, то такая таблица задает выборочное распределение
x 1
n 1
x 2
n 2
x 3
n 3
…
…
x n
n n
x 1
n 1 /n
x 2
n 2 /n
x 3
n 3 /n
…
…
x n
n n /n

Пример.
Для выборки определить объем, размах, найти статистический ряд и выборочное распределение:
3, 8, -1, 3, 0, 5, 3, -1, 3, 5
Объем: n = 10, размах = 8 – (-1) =9
Статистический ряд:
Выборочное распределение:
x i
n i
-1
0
2
3
1
5
4
2
8
1
x i
-1
0
0,2
3
0,1
5
0,4
0,2
8
0,1
(убеждаемся 0,2 + 0,1 + 0,4 + 0,2 + 0,1 = 1)

Мода ( m o ) — это наиболее частое значение в выборке, или среднее значение класса с наибольшей частотой. Мода как центральная тенденция используется чаще всего для того, чтобы дать общее представление о распределении. В некоторых случаях у распределения могут быть две моды, в таком случае это свидетельствует о бимодальном распределении, что указывает на наличие двух относительно самостоятельных групп.
Медиана ( m e ) соответствует центральному значению в последовательном ряду всех полученных значений выстроенном в порядке возрастания. Если же в ряду чётное количество показателей , то берут среднее арифметическое двух средних значений

Среднее арифметическое ( m ) — это показатель центральной тенденции, полученный делением суммы всех значений данных на число
этих данных. Среднее
арифметическое используется для
представления количественных
переменных с нормальным
распределением.
Указание в представлении данных
меры центральной тенденции
(среднее, медиана, мода)
автоматически сообщает
о нормальности распределения
признака .
При нормальном распределении все три показателя
более или менее совпадают , а при асимметричном распределении — нет .
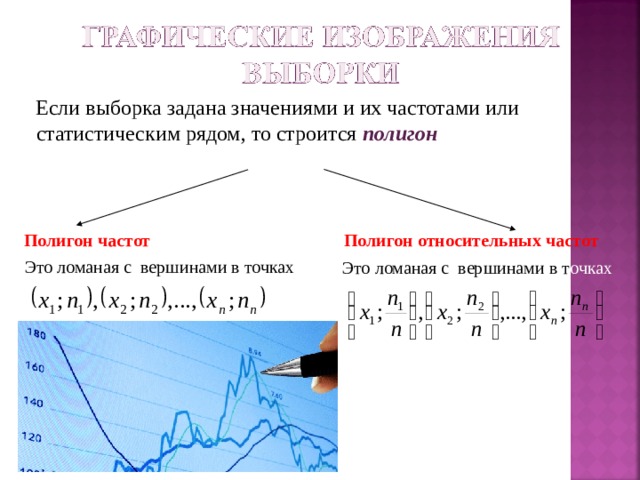
Если выборка задана значениями и их частотами или статистическим рядом, то строится полигон
Полигон частот Полигон относительных частот
Это ломаная с вершинами в точках
Это ломаная с вершинами в т очках

При большом объеме выборки строится гистограмма
Гистограмма частот гистограмма относительных частот
Для построения гистограммы промежуток от наименьшего значения выборки до наибольшего разбивают на несколько частичных промежутков длины h
Для каждого частичного промежутка подсчитывают сумму частот значений выборки, попавших в этот промежуток ( S i ) .
Значение выборки, совпавшее с правым концом частичного промежутка (кроме последнего промежутка), относится к следующему промежутку
Затем на каждом промежутке, как на основании, строим прямоугольник с высотой
Ступенчатая фигура, состоящая из таких прямоугольников, называется гистограммой частот .
Площадь такой фигуры равна объёму выборки .

Гистограммой относительных частот называют ступенчатую фигуру, состоящую из прямоугольников, основанием которых являются частичные промежутки длины h , а высотой отрезки длиной
где i – сумма относительных частот значений выборки , попавших в i промежуток
Площадь такой фигуры равна 1
Пример.
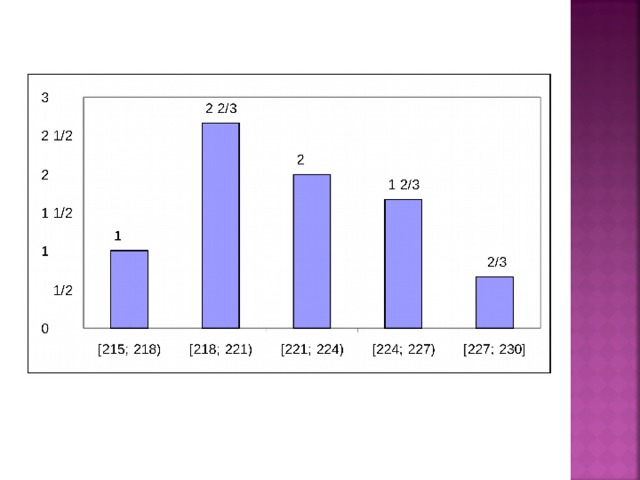
В результате измерения напряжения в электросети получена выборка. Построить гистограмму частот, если число частичных промежутков равно 5

218, 224, 222, 223, 221, 220, 227, 216, 215, 220, 218, 224, 225, 219, 220, 227, 225, 221, 223, 220, 217, 219, 230, 222
n = 24
Наибольшее значение – 230
Наименьшее значение – 215
Интервал: 230 – 215 = 15
Длина частичных промежутков:
Составим таблицу:
![№ интервал 1 2 [215; 218) [218; 221) 3 3 [221; 224) 4 8 6 [224; 227) 5 4 [227; 230] 3](https://fsd.videouroki.net/html/2020/01/08/v_5e162733c9956/img27.jpg)
№
интервал
1
2
[215; 218)
[218; 221)
3
3
[221; 224)
4
8
6
[224; 227)
5
4
[227; 230]
3

Для выборки объема n
Выборочное статистическое ожидание (выборочное среднее) – это среднее арифметическое значений выборки
Если выборка задана статистическим рядом, то

Выборочная дисперсия – это среднее арифметическое квадратов отклонений значений выборки от выборочного среднего
Если выборка задана статистическим рядом, то

Несмещенная выборочная дисперсия
Пример.
Для выборки найти
Выборка: 4, 5, 3, 2, 1, 2, 0, 7, 7, 3
n = 10
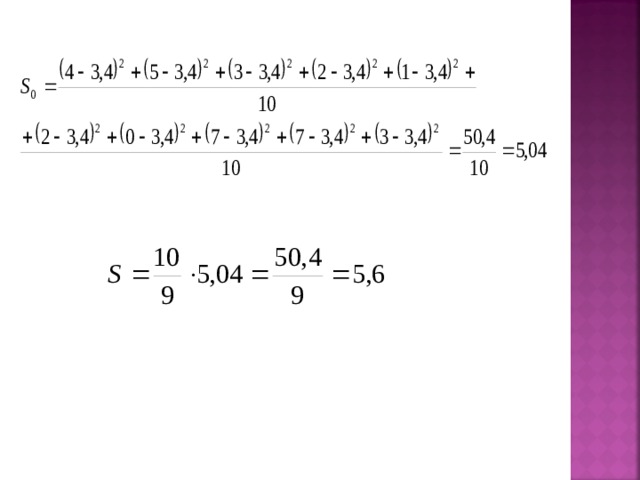









 Презентация Математическая статистика (3.82 MB)
Презентация Математическая статистика (3.82 MB)
 0
0 1953
1953 291
291 Нравится
0
Нравится
0






