 Получите свидетельство
Получите свидетельство Вход
Вход



Строки: индексы и срезы

Строка представляет собой упорядоченный набор символов.
Это значит, что каждый символ в строке занимает свое место - индекс .

индекс может быть как положительным так и отрицательным: положительные индексы – это отсчет от левого края, а отрицательные – от правого.
Причем отсчет символов от левого края начинается с 0, а с правого начинается с −1(минус единицы).
![для обращения к тому или иному символу используется следующий синтаксис: [] s](https://static.multiurok.ru/videouroki/html/2023/01/11/v_63bed10a282bb/img3.jpg)
для обращения к тому или иному символу используется следующий синтаксис:
[]
s
![Срезы Часто в программировании требуется выбрать не один какой-то символ, а сразу несколько. Для этого используются так называемые срезы. Их работу проще показать на конкретных примерах. Пусть у нас есть наша строка: s =Hello world! и мы хотим выделить последнее слово «world!». Для этого в квадратных скобках указывается начальный индекс и через двоеточие – конечный. Если мы запишем все вот в таком виде: s[6:10] 'word'](https://static.multiurok.ru/videouroki/html/2023/01/11/v_63bed10a282bb/img4.jpg)
Срезы
Часто в программировании требуется выбрать не один какой-то символ, а сразу несколько. Для этого используются так называемые срезы. Их работу проще показать на конкретных примерах. Пусть у нас есть наша строка:
s =Hello world!
и мы хотим выделить последнее слово «world!». Для этого в квадратных скобках указывается начальный индекс и через двоеточие – конечный. Если мы запишем все вот в таком виде:
s[6:10]
'word'
 s[1::2] 'el od' изменить значение в строке s=s[:4]+'a'+s[5:] s 'hella word' Строка в обратном порядке s='xcjfh' s[::-1] 'hfjcx' " width="640"
s[1::2] 'el od' изменить значение в строке s=s[:4]+'a'+s[5:] s 'hella word' Строка в обратном порядке s='xcjfh' s[::-1] 'hfjcx' " width="640"
срез строки до конца
s[7:]
'ord‘
срез до
s[:4]
'hell”
вся строка
s[:]
'hello word'
срез через одну букву (четные буквы)
s[::2]
'hlowr‘
не четные буквы:
s[1::2]
'el od'
изменить значение в строке
s=s[:4]+'a'+s[5:]
s
'hella word'
Строка в обратном порядке
s='xcjfh'
s[::-1]
'hfjcx'

Функция in в строках
В Python существует всего 2 оператора принадлежности —
in и not in и предназначены они для проверки наличия элемента в строке (str), списке (list), словаре (dict) или кортеже (tuple).
in — возвращает True если элемент присутствует в последовательности;
not in — возвращает True если элемент отсутствует в последовательности.

примеры
 'c''C' True ord('C') 67 ord('c') 99 Сравнение происходит последовательно: первый символ одной строки сравнивается с первым символом другой. Если они равны, сравниваются символы на следующей позиции. Все символы имеют разные значения Unicode или ASCII. Компьютер сравнивает не символы как таковые, а их значения в Unicode. Чем больше это значение, тем «больше» символ . операторы сравнения: , = " width="640"
'c''C' True ord('C') 67 ord('c') 99 Сравнение происходит последовательно: первый символ одной строки сравнивается с первым символом другой. Если они равны, сравниваются символы на следующей позиции. Все символы имеют разные значения Unicode или ASCII. Компьютер сравнивает не символы как таковые, а их значения в Unicode. Чем больше это значение, тем «больше» символ . операторы сравнения: , = " width="640"
Сравнение строк
'c''C'
True
ord('C')
67
ord('c')
99
Сравнение происходит последовательно: первый символ одной строки сравнивается с первым символом другой. Если они равны, сравниваются символы на следующей позиции. Все символы имеют разные значения Unicode или ASCII. Компьютер сравнивает не символы как таковые, а их значения в Unicode. Чем больше это значение, тем «больше» символ .
операторы сравнения: , =

Функция ord
Функция Python ord-это встроенная функция, которая возвращает целое число, представляющее код Юникода указанного символа. Другими словами, в Python каждому символу Юникода присвоено целое число.

UNICODE
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256).
В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет на много больше.
Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — э того достаточно, чтобы вместить все символы всех языков мира. Большую часть символов “Unicode” занимают китайские, корейские и японские иероглифы.
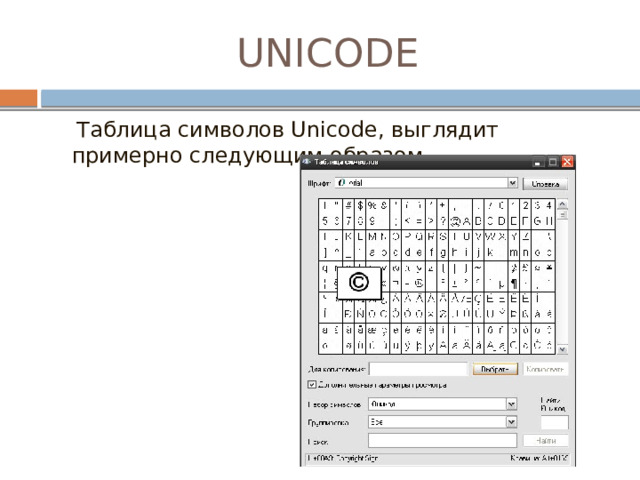
UNICODE
Таблица символов Unicode, выглядит примерно следующим образом

Текстовые кодировки
Десятичные коды некоторых символов в
различных кодировках









 Строки и индексы (1.98 MB)
Строки и индексы (1.98 MB)
 0
0 862
862 6
6 Нравится
0
Нравится
0



