 Получите свидетельство
Получите свидетельство Вход
Вход



Цель: сформировать у учащихся представление о том, как в компьютере кодируется текстовая информация.
Требования к знаниям и умениям:
Учащиеся должны знать:
- принцип кодирования текстовой информации;
- что такое таблица кодов ASCII.
Учащиеся должны уметь:
- кодировать и декодировать символы с помощью таблицы кодов;
- находить информационный объем текстов и сообщений.
Программно-дидактическое обеспечение: ПК, таблицы кодов, текстовый редактор, калькулятор.
Ход урока
- Постановка целей урока
1. Как кодируются символы в компьютере? Почему именно так, а не иначе?
2. Всегда ли разные компьютеры «понимают» друг друга? Почему?
3. Сколько текстов поместится на дискете? А на жестком диске?
- Актуализация знаний
1. Как в компьютере кодируются символы?
2. Что такое «компьютерный алфавит»? Какова его мощность?
3. Чему равен информационный объем одного символа компьютерного алфавита?
- Изложение нового материала
Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации.
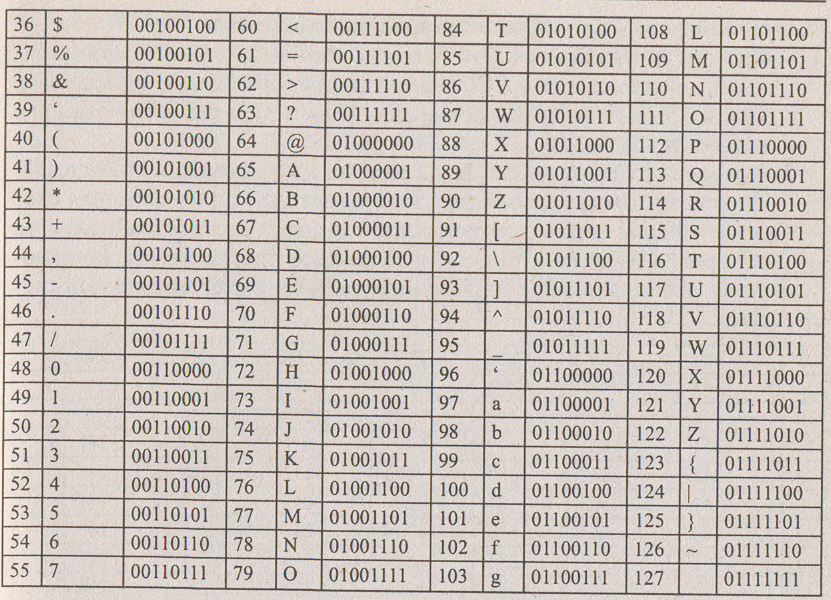
1. Таблица кодирования ASCII
Традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, Т.е. необходимо было выработать стандарт - все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в Институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (American Standard Code fог Information Interchange - стандартный кон информационного обмена США).
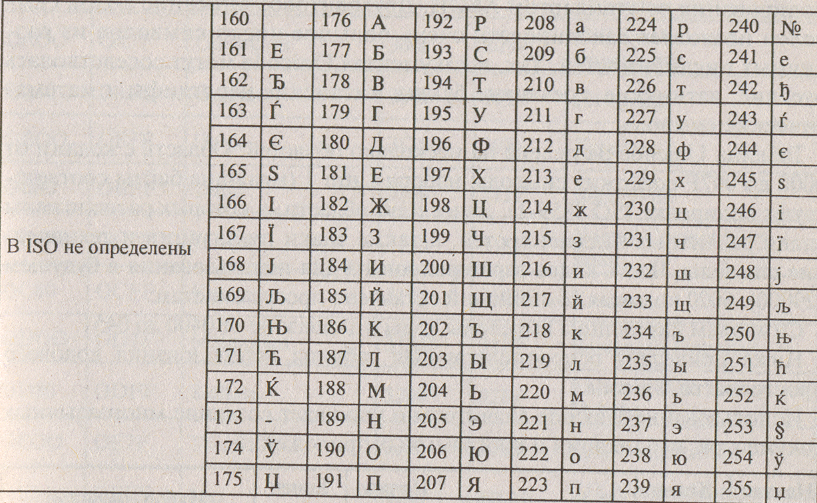
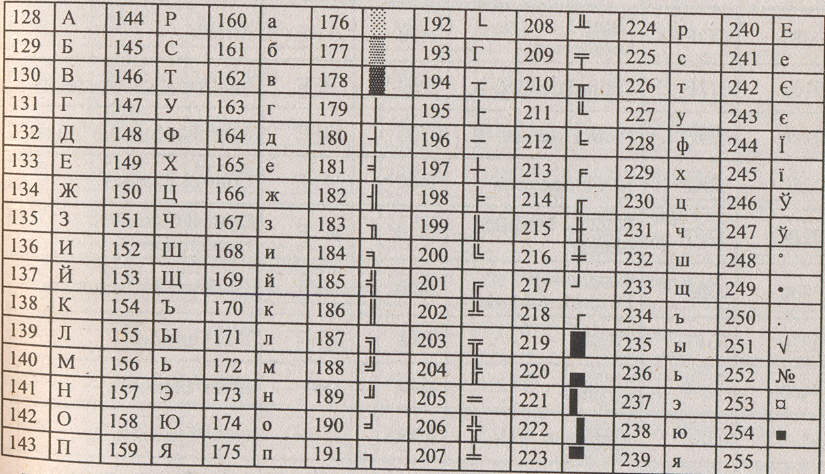
Рассмотрим таблицу кодов ASCII.
Пояснение: распечатать на всех детей таблицу и раздать им.
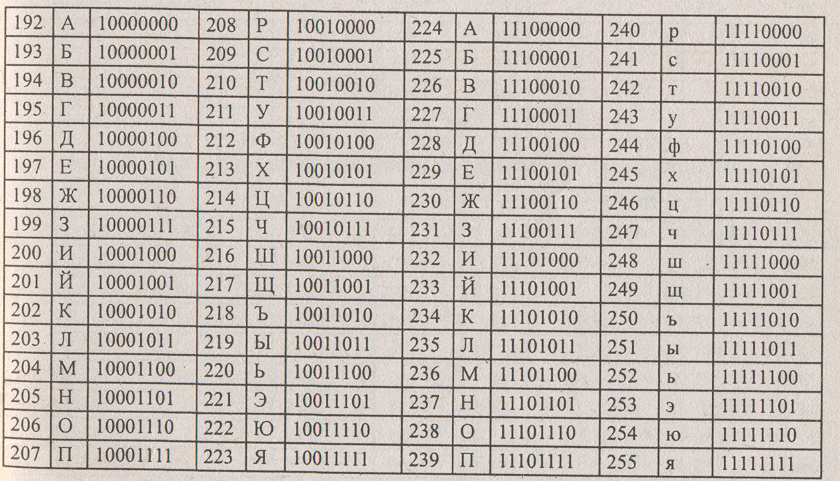
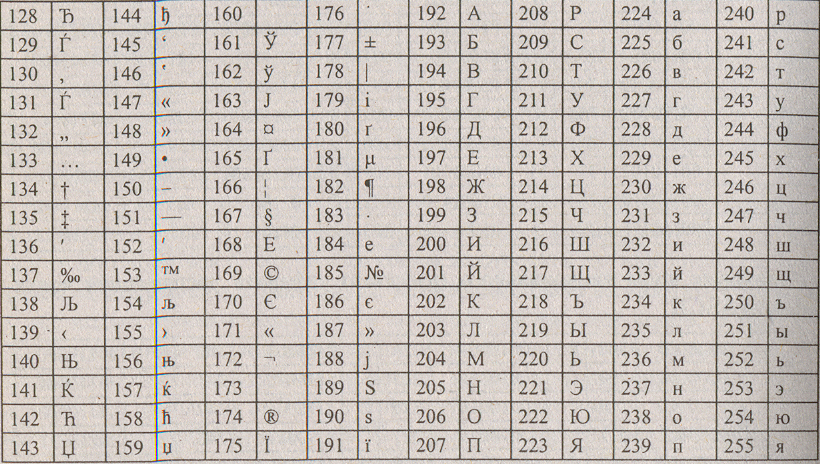
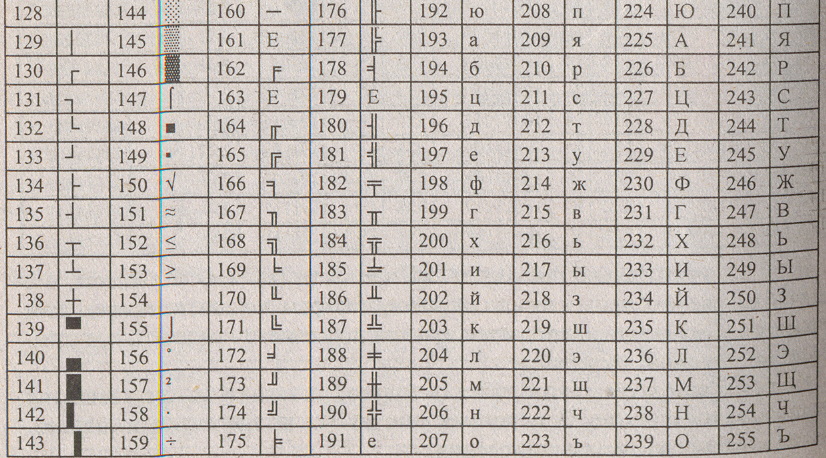
Таблица ASCII разделена на две части. Первая - стандартная - содержит коды от 0 до 127. Вторая - расширенная - содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Коды цифр берутся из таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
2. Альтернативные системы кодирования кириллицы
1. Система кодирования КОИ-7 (код обмена информацией, семизначный), действовавшая в СССР. Была вскоре вытеснена американским: кодом ASCII во вторую, расширенную часть системы кодирования с кодами от 128 по 255.
2. Кодировка Windows-1251. Была введена извне компанией Мiсrosоft. Так как программный продукт этой компании - операционная система Windows глубоко закрепилась и широко распространилась, то кодировка Windows-1251 получила широкое применение на компьютерах, работающих под управлением именно этой операционной системы.
3. Кодировка КОИ-8 широко распространена на территории России и в российском секторе Интернета.
4. Кодировка ISO (lntemational Standard Organization – Международный институт стандартизации) - содержит символы русского алфавита, но на практике используется редко.
5. Кодировка ГОСТ - альтернативная. Действует на компьютерах в операционных системах MS-DOS.
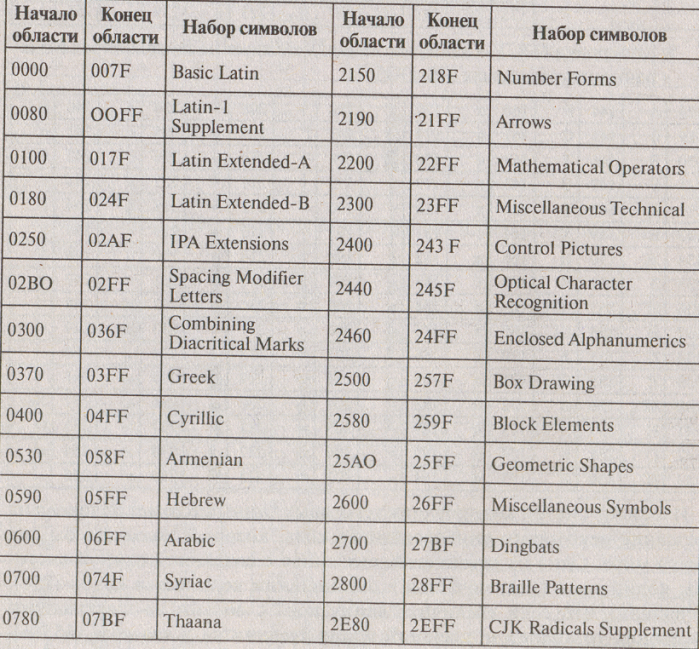
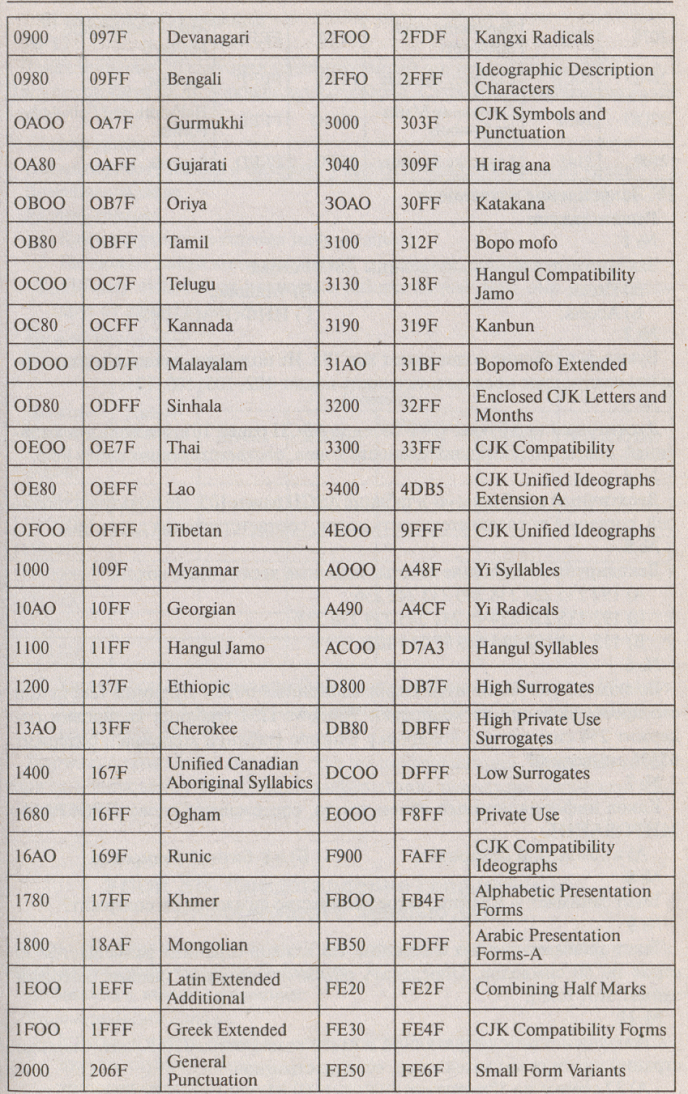
Изобилие систем кодирования текстовых данных толкает человека на создание некоторого универсального кода, который подходил бы для всего мира. Одна из трудностей, связанная с созданием единой системы кодирования, заключается в ограничении количества кодов (256). Очевидно, что если увеличить длину кода с восьми до шестнадцати разрядов, то диапазон значений кодов увеличится в два раза (65536). Такая система была создана и названа UNICODE. Для представления каждого символа в этом стандарте используются два байта: один байт для кодирования символа, другой для кодирования признака. Тем самым обеспечивается информационная совместимость данного способа кодирования со стандартом ASCII. Двухбайтовое описание кодов символов позволяет закодировать очень большое число символов из различных письменностей. Так, в документах Unicode могут соседствовать русские, латинские, греческие буквы, китайские иероглифы и математические символы.
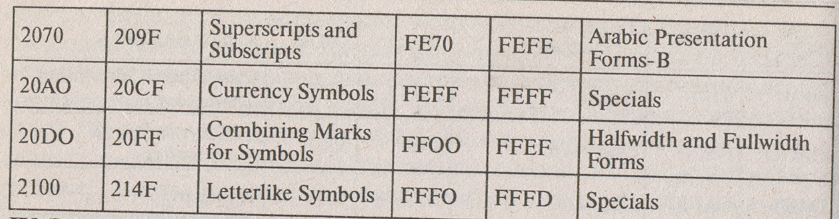
Таблица Unicode разделена на несколько областей. Область с кодами от 0000 до 007F содержит символы набора Latin 1 (младшие байты соответствуют кодировке ISO 8859-1). Далее идут области, в которых расположены знаки различных письменностей, а также знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем (29000). 6000 кодовых комбинаций оставлено программистам.
Символам кириллицы выделены коды в диапазоне от 0400 до 0451.
Использование Unicode значительно упрощает создание многоязычных документов, публикаций и программных приложений.
- Закрепление изученного
Решите задачи:
№1. Закодируйте с помощью таблицы ASCII слова:
А) Excel; Б) Access; В) Windows; Г) ИНФОРМАЦИЯ.
№2. Буква «i» в таблице кодов имеет код 105. Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
№3. Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help.
№4. Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link.
№5. Декодируйте следующие тексты, заданные десятичным кодом:
А) 192 235 227 238 240 232 242 236;
Б) 193 235 238 234 45 241 245 229 236 224;
В) 115 l1l 102 116 119 97 114 101.
№6. Во сколько раз увеличится информационный объем страницы текста при его преобразовании из кодировки Windows 1251 (таблица кодировки содержит 256 символов) в кодировку Unicode (таблица кодировки содержит 65536 символов)?
№7. Каков информационный объем текста, содержащего слово ПРОГРАММИРОВАНИЕ:
А) в 16-битной кодировке; Б) в 8-битной кодировке.
№8. Текст занимает ¼ Кбайта. Какое количество символов он содержит?
№9. Текст занимает полных 6 страниц. На каждой странице размещается 30 строк по 80 символов. Определить объем оперативной памяти, который займет этот текст.
№10. Свободный объем оперативной памяти компьютера 320 Кбайт. Сколько страниц книги поместится в ней, если на странице:
А) 32 строки по 32 символа; Б) 64 строки по 64 символа; В) 16 строк по 32 символа.
№11. Текст занимает 20 секторов на двусторонней дискете объемом 360 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст?
- Итог урока
Оцените работу класса и назовите учащихся, отличившихся на уроке.
Домашнее задание – смотри архив.










 Представление текстовой информации в компьютере (8.68 MB)
Представление текстовой информации в компьютере (8.68 MB)
 0
0 2908
2908 431
431 Нравится
0
Нравится
0



