 Получите свидетельство
Получите свидетельство Вход
Вход



2.1. Кодирование текстовой информации
 256 = 2 I = 2 8 = 2 I = I = 8 битов. " width="640"
256 = 2 I = 2 8 = 2 I = I = 8 битов. " width="640"
Двоичное кодирование текстовой информации в компьютере
Текстовая информация – это информация, выраженная с помощью естественных и формальных языков в письменной форме
Для представления текстовой информации (прописные и строчные буквы русского и латинского алфавитов, цифры, знаки и математические символы) достаточно 256 различных знаков.
По формуле N=2 I можно вычислить, какое количество информации несет в себе каждый знак:
N = 2 I = 256 = 2 I = 2 8 = 2 I = I = 8 битов.

Для обработки текстовой информации на компьютере необходимо представить ее в двоичной знаковой системе (в виде 0 и 1).
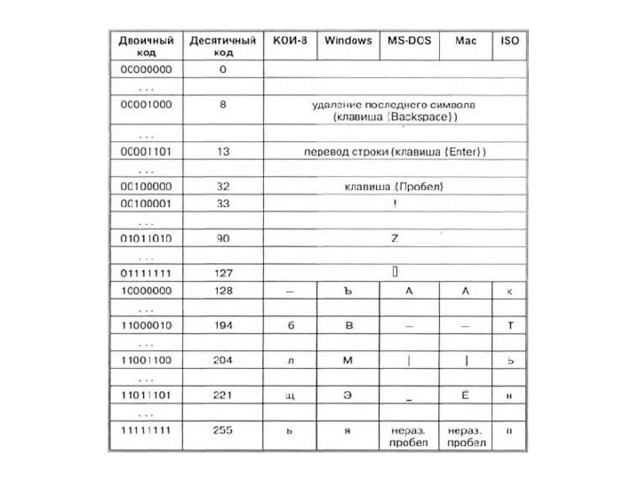
Для кодирования каждого знака требуется количество информации, равное 8 битам, т. е. длина двоичного кода знака составляет восемь двоичных знаков. Каждому знаку необходимо поставить в соответствие уникальный двоичный код из интервала от 00000000 до 11111111 (в десятичном коде от 0 до 255)

Человек различает знаки по их начертанию, а компьютер - по их двоичным кодам. При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение знака преобразуется в его двоичный код.
Пользователь нажимает на клавиатуре клавишу со знаком, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код знака).
Код знака хранится в оперативной памяти компьютера, где занимает одну ячейку (1 байт).
В процессе вывода знака на экран компьютера производится обратное перекодирование, т. е. преобразование двоичного кода знака в его изображение.
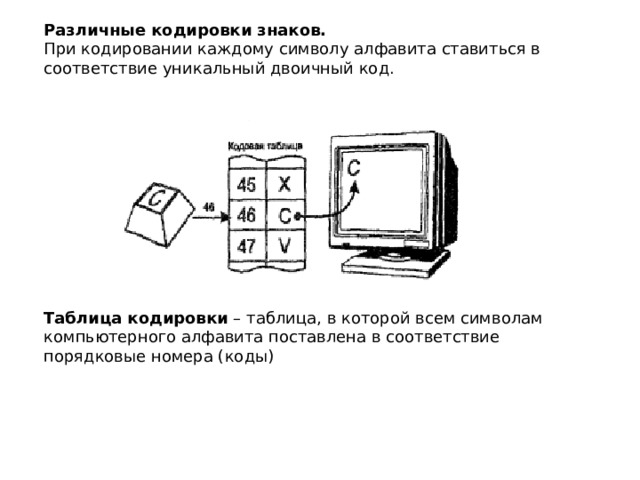
Различные кодировки знаков.
При кодировании каждому символу алфавита ставиться в соответствие уникальный двоичный код.
Таблица кодировки – таблица, в которой всем символам компьютерного алфавита поставлена в соответствие порядковые номера (коды)

Присваивание знаку конкретного двоичного кода - это вопрос соглашения, которое фиксируется в кодовой таблице.
В существующих кодовых таблицах:
- десятичные коды с 0 по 32 соответствуют не знакам, а операциям (перевод строки, ввод пробела и т. д.).
- десятичные коды с 33 по 127 являются интернациональными и соответствуют знакам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
- десятичные коды с 128 по 255 являются национальными, т. е. в различных национальных кодировках одному и тому же коду соответствуют разные знаки.
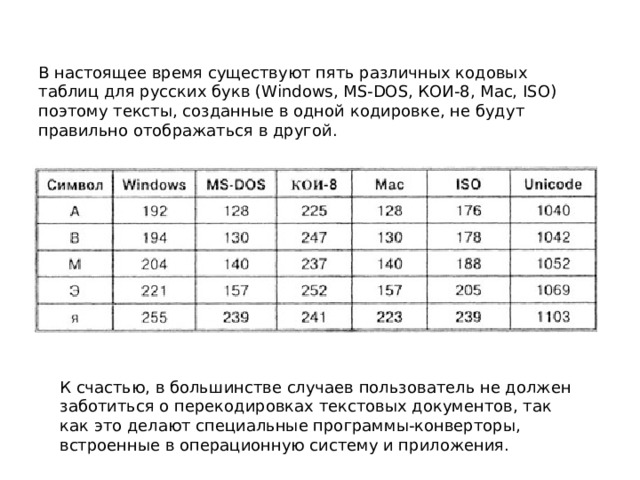
В настоящее время существуют пять различных кодовых таблиц для русских букв (Windows, MS-DOS, КОИ-8, Mac, ISO) поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в операционную систему и приложения.

В последние годы широкое распространение получил новый международный стандарт кодирования текстовых символов Unicode, который отводит на каждый символ 2 байта (16 битов). По формуле можно определить количество символов, которые можно закодировать согласно этому стандарту: N = 2 I = 2 16 = 65 536.
Такого количества символов достаточно, чтобы закодировать не только русский и латинский алфавиты, цифры, знаки и математические символы, но и греческий, арабский, иврит и другие алфавиты.
Стандарт Unicode со временем изменяется и расширяется, известен ряд версий стандарта. Начиная с версии 6.0 (релиз в 2010 г.) в раздел «символы жестов» (англ. gesture symbols ) включены отдельные изображения трёх обезьян . Коды Unicode-символов «не вижу», «не слышу», «не говорю» соответственно 1F648, 1F649 и 1F64A.









 Кодирование текстовой информации (630.5 KB)
Кодирование текстовой информации (630.5 KB)
 0
0 150
150 2
2 Нравится
0
Нравится
0


