 Получите свидетельство
Получите свидетельство Вход
Вход


Многие пользователи в большинстве случаев не обращают особого внимания на сжатие (архивацию) различных данных. Мало кто задумывается о том, что этот процесс окружает практически все действия персонального компьютера. Почти все файлы, находящиеся на нашем с вами ПК, начиная от инсталляционного файла любой программы, заканчивая аудио или видео содержимым используют определенный тип сжатия, с потерей или без потери самых данных (зависит от архиватора и типа сжатия).
Резервные архивы, как правило, занимают значительное место на диске, особенно если речь идет о копировании жесткого диска в целом или его разделов. Поэтому при создании архива стоит обратить внимание на сжатие данных. Есть несколько вариантов выполнения данной процедуры. Выбор того или иного варианта может быть мотивирован размерами доступного дискового пространства или же временем, имеющимся в распоряжении пользователя. Так, сжатие данных может быть выполнено предельно быстро с оптимальным для данной скорости коэффициентом сжатия. Если время не столь критичный фактор, то есть возможность выполнить максимальное сжатие. В этом случае, естественно, процедура будет протекать дольше. Сразу при выборе уровня сжатия, можно оценить и размер конечного архива. Он определяется размерами копируемого жесткого диска или его раздела, а также выбранным уровнем сжатия.
Как хранение, так и передача информации обходятся участникам информационного процесса недешево. Зная стоимость носителя и его емкость (Мбайт, Гбайт), нетрудно подсчитать, во что обходится хранение единицы информации, а зная пропускную способность канала связи (Мбит/с) и стоимость его аренды, можно определить затраты на передачу единицы информации (если не без лимитный тариф). Полученные результаты обычно составляют вполне значимые величины как для корпоративных пользователей, так и для индивидуальных. В связи с этим, регулярно возникает необходимость сжимать данные перед тем, как размещать их в архивах или передавать по каналам связи. Соответственно, существует и обратная необходимость восстановления данных из предварительно уплотненных архивов.
Из выше изложенного, очевидно, что при изучении информационных технологий тема «Сжатие (архивация) данных» достаточно важна.
Однако, при всем многообразии различных методов сжатия определенного типа данных и соответствующих им архиваторов, на уроках информатики в худшем случае дается обзор наиболее популярных архиваторов и инструкция по работе пользователя. Удовлетворительно, когда при изучении темы рассматриваются методы сжатия данных, проводятся лабораторные работы, позволяющие сравнить эффективность степени сжатия различных архиваторов, степень сжатия разных по типу файлов и однотипных файлов с разным количеством входящих в них элементов (символы для текстовых файлов, пиксели для графических файлов и т. д. ) в определенном архиваторе.
Но что происходит с данными при работе программы - архиватора остается неизвестным.
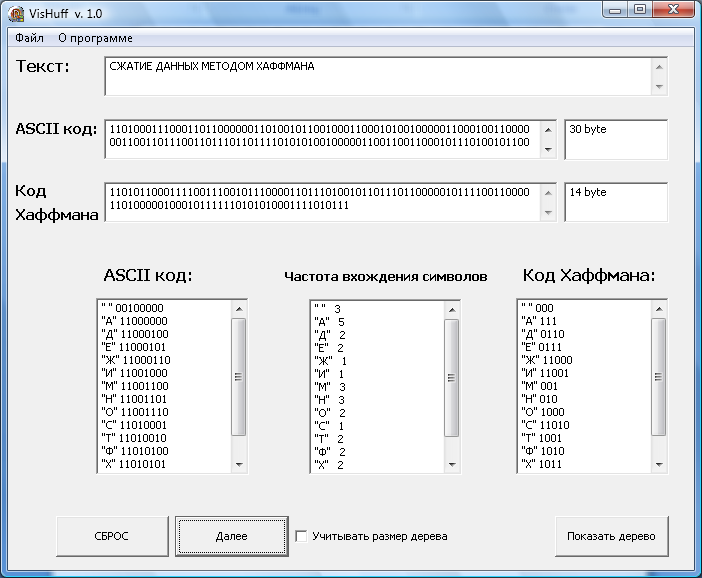
На уроках по теме «Архивация данных» мы знакомимся с одним из первых алгоритмов эффективного кодирования информации, который был предложен Д. А. Хаффманом в 1952 году.
Идея алгоритма состоит в следующем: зная вероятности вхождения символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Коды Хаффмана имеют уникальный префикс, что и позволяет однозначно их декодировать, несмотря на их переменную длину.
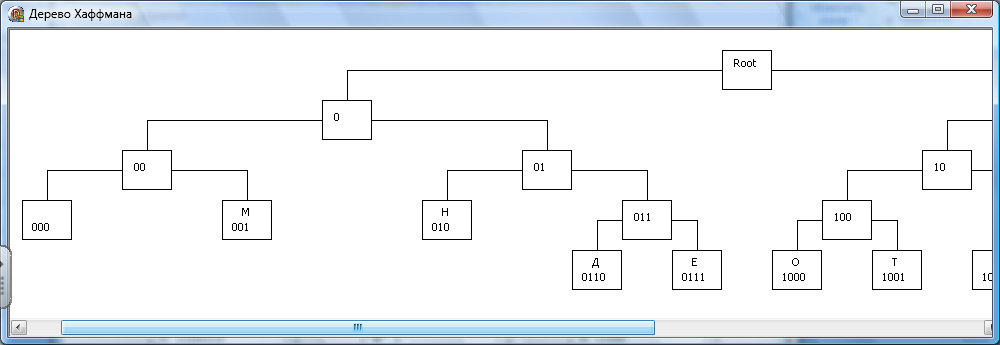
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н - дерево). Алгоритм построения Н - дерева прост и элегантен.
1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
2. Выбираются два свободных узла дерева с наименьшими весами.
3. Создается их родитель с весом, равным их суммарному весу.
4. Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка.
5. Одной ветви дерева, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
6. Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.

Весь материал – смотрите документ.

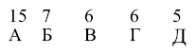
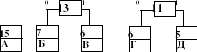 рис.1
рис.1 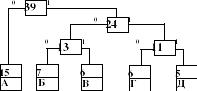 рис.2
рис.2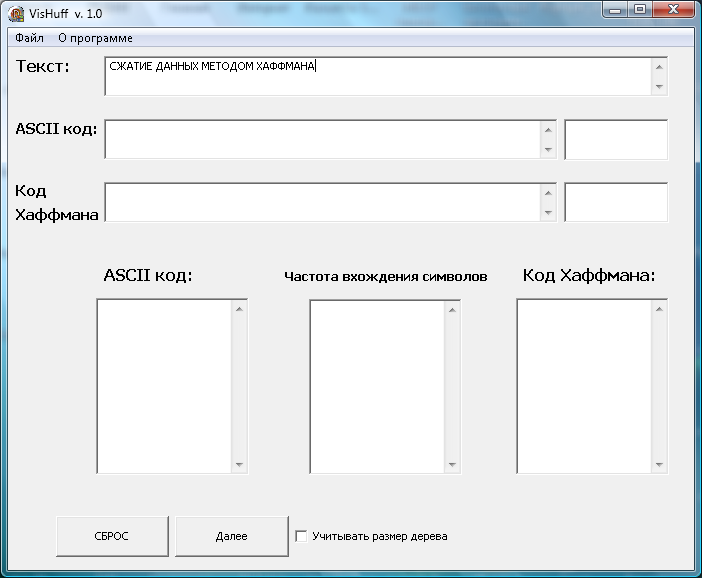









 Изучение темы по информатике "Архивация данных" (0.17 MB)
Изучение темы по информатике "Архивация данных" (0.17 MB)
 0
0 797
797 55
55 Нравится
0
Нравится
0


