 Получите свидетельство
Получите свидетельство Вход
Вход



Алфавитный подход к измерению информации
Подготовил преподаватель Бурдин А.Б.

Существуют два подхода к измерению информации. Алфавитный – отталкивается от практических нужд хранения и передачи информации в технических системах и не связан со смыслом (содержанием) информации . Содержательный рассматривает восприятие информации человеком и поэтому имеет дело со смыслом информации .

Алфавитный подход применяется в цифровых (компьютерных) системах хранения и передачи информации, в которых используется двоичный способ кодирования информации.
Его называют ещё объемным подходом .

При алфавитном подходе для определения количества информации имеет значение лишь размер (объем) хранимого и передаваемого кода .
!
N = 2 i
Хартли
i – информационный вес символа алфавита
N – мощностью алфавита .
Если, например, i = 2, то можно построить 4 двухразрядные комбинации из нулей и единиц, т.е. закодировать 4 символа .
i = 2 :
00
01
10
11

!
N = 2 i
При i = 3 существует 8 трехразрядных комби-наций нулей и единиц (кодируется 8 символов):
i=3 :
000
001
010
011
100
101
110
111
Английский алфавит содержит 26 букв . Для записи текста нужны еще как минимум шесть символов: пробел, точка, запятая, вопросительный знак, восклицательный знак, тире .
В сумме получается расширенный алфавит мощностью 32 символа .

Поскольку 32 = 2 5 , все символы можно закодировать всевозможными пятиразряд-ными двоичными кодами от 00000 до 11111.
Именно пятиразрядный код использовался в телеграфных аппаратах, появившихся еще в XIX веке.
Телеграфный аппарат при вводе переводил английский текст в двоичный код, длина которого в 5 раз больше, чем длина исходного текста.
!
В двоичном коде каждая двоичная цифра несет одну единицу информа-ции, которая называется 1 бит .

!
БИТ является основной минимальной единицей измерения информации.
Информационный вес символа – это длина двоичного кода, с помощью которого кодируется символ алфавита .
Информационный объем текста складывается из информационных весов всех составляющих текст символов. Например, английский текст из 1000 символов в телеграфном сообщении будет иметь информационный объем 5000 битов .

Алфавит русского языка включает 33 буквы . Если к нему добавить еще пробел и пять знаков препинания, то получится набор из 39 символов . Для двоичного кодирования символов такого алфавита пятиразрядного кода уже недостаточно. Нужен как минимум 6-разрядный код . Поскольку 2 6 = 64, то остается еще резерв для 25 символов.
Его можно использовать для кодирования цифр, всевозможных скобок, знаков математических операций и других символов, встречающихся в русском тексте.
Следовательно, информационный вес символа в расширенном русском алфавите будет равен 6 битам . А текст из 1000 символов будет иметь объем 6000 битов.

Информационный объем текста равен
I = К × i (битов) .
i – информационный вес символа алфавита .
К – количество символов в тексте.
Для определения информационного веса символа полезно знать ряд целых степеней двойки. Вот как он выглядит в диапазоне от 2 1 до 2 10
i
2 i
1
2
2
3
4
4
8
16
5
6
32
64
7
128
8
256
9
10
512
1024

Поскольку мощность N алфавита может не являться целой степенью двойки, информационный вес символа алфавита мощности N определяется следующим образом. Находится ближайшее к N значение во второй строке таблицы, не меньшее N . Соответствующее значение i в первой строке будет равно информационному весу символа.
Пример . Определим информационный вес символа алфавита, включающего в себя все строчные и прописные русские буквы (66); цифры (10); знаки препинания, скобки, кавычки (10). Всего получается 86 символов .
Поскольку 2 6 7 , информационный вес символа данного алфавита равен 7 битам .
Это означает, что все 86 символов можно закодировать семиразрядными двоичными кодами .

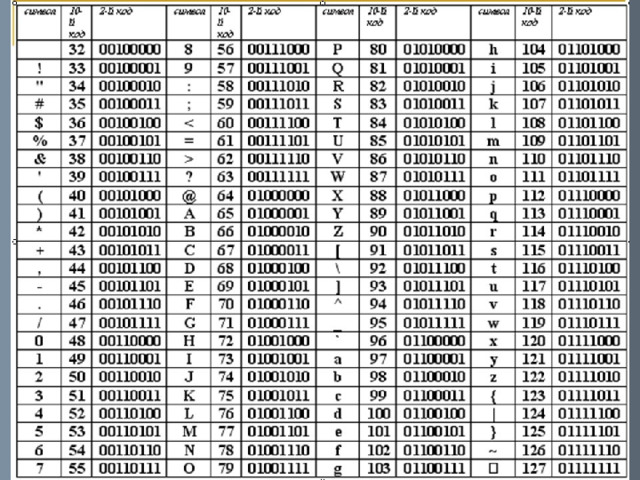
В ОС Windows для двоичного представления текстов применяется расширенная кодовая таблица ANSI, которая имеет восьмиразрядный код .
С помощью восьмиразрядного кода можно закодировать алфавит из 256 символов , поскольку
256 = 2 8 .
!
Более крупной, чем бит, единицей измерения информации является байт : 1 байт = 8 битов .
Помимо бита и байта, для измерения информации используются и более крупные единицы:
1 бит
1 байт = 8 бит
1 Кб (килобайт) = 2 10 байтов = 1024 байта ;
1 Мб (мегабайт) = 2 10 Кб = 1024 Кб ;
1 Гб (гигабайт) = 2 10 Мб = 1024 Мб ;
1 Тб (терабайт) = 2 10 Гб = 1024 Гб .

Во всем миру существует единое соглашение о распределении этих 256 комбинаций (кодов компьютерных символов):
- Коды с 0 по 32 – операции (перевод, строки, ввод пробела,…)
- Коды с 33 по 127 – интернациональные – символы латинского алфавита, цифры, знаки
- Коды с 128 по 255 – национальные символы (в каждой стране разные).
Кодовые страницы с русским алфавитом есть во всех операционных системах:
Windows, MS-DOS, Мас.


Также разработан международный стандарт Unicode , в котором каждому символу отводится не один, а два байта . С его помощью можно закодировать все существующие алфавиты на Земле .
Вопрос . Почему возможно закодировать все существующие алфавиты с помощью Unicode ?
2 16 = 65 536

ПРИВЕТ символов 6 х 8 бит = 48 бит = 6 байт
ПРИВЕТ ДРУГ — 11 с. х 2 байта = 22 байта
В компьютере любые виды информации – тексты, числа, изображения, звук – представляются в форме двоичного кода .
!
Объем информации любого вида, выраженный в битах, равен длине двоичного кода, в котором эта информация представлена.

Использованная литература:
Л-1, стр. 12-16.
Семакин И.Г. Информатика. 10 кл., 1 часть.

Самостоятельная (внеаудиторная) работа:
Задачи на перевод из одной системы счисления в другую
Цель : Научиться переводить десятичные числа в другие системы счисления и наоборот.
Задание : изучить материал Л-1 (Семакин И.Г. Информатика 10 кл. Ч.1) стр.30-34. Выполнить задания – решить в тетради.









 Алфавитный подход к измерению информации (963.98 KB)
Алфавитный подход к измерению информации (963.98 KB)
 0
0 478
478 7
7 Нравится
0
Нравится
0


