 Получите свидетельство
Получите свидетельство Вход
Вход



Вопросы:
· Определение символьной строки.
· Методы обработки строк.
Символьной строкой называется набор нумерованных символов, которые хранятся в оперативной памяти компьютера под одним именем и располагаются последовательно друг за другом. Индексы символов строки, как и индексы элементов списка, начинаются с нуля. Многие из вас наверняка обратили внимание на то, что это определение строки похоже на определение списка. Во многих языках программирования действительно символьные строки можно определить, как списки символов, для обработки которых определён ряд дополнительных инструментов, но в языке Python это не совсем так. Главное отличие символьной строки от списка состоит в том, что символьная строка – это неизменяемая величина. На практике это означает, что к символу строки можно обратиться, как и к элементу списка, указав его индекс, однако в отличие от элемента списка, символ строки таким образом изменять нельзя.
Однако над строками можно выполнять целый ряд других действий. Рассмотрим операции, реализованные для обработки символьных строк. Первая из них – сцепление строк. Она записывается знаком арифметического сложения между сцепляемыми строками. Результат этой операции – новая строка, состоящая из исходных.

Выделить часть строки можно, как и часть списка. Подробнее рассмотрим, как это работает. Выделение части строки происходит по номерам её срезов. Номер среза строки соответствует индексу символа строки, перед которым он располагается, то есть перед нулевым символом следует нулевой срез, а перед i-тым символом, соответственно, i-тый.

Для того, чтобы выделить часть строки, после названия строки в квадратных скобках, через двоеточие, нужно указать 2 числа – номера срезов строки, между которыми располагается часть строки, которую нужно выделить. При этом если номер первого среза – 0, то его можно не указывать, точно так же можно не указывать номер второго среза, если он равен длине строки. Если в качестве номеров срезов указываются отрицательные числа, то к ним автоматически прибавляется длина строки.
s[0 : len (s)] == s[ : ]
s[-5 : -1] == s[len(s) – 5 : len(s) – 1]
Рассмотрим несколько полезных методов для обработки строк. Методы upper и lower изменяют регистр всех символов строки, соответственно, на верхний и нижний. Логический метод isdigit проверяет, только ли цифры содержит строка. Он возвращает значение «истина», если строка состоит только из цифр, в противном случае будет возвращено значение «ложь». Этот метод можно использовать для того, чтобы определить, является ли строка целым положительным числом. Для отрицательных чисел и для чисел с плавающей точкой этот метод будет возвращать значение «ложь».

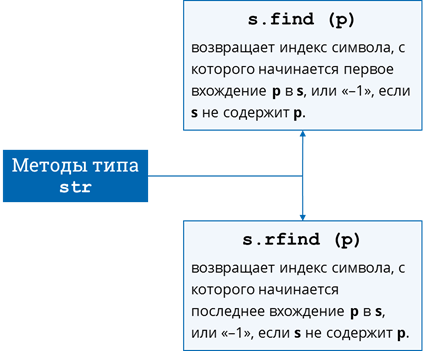
Часто бывает полезен метод find. Он возвращает индекс элемента, с которого начинается первое вхождение заданной подстроки в строку, или же -1, если заданной подстроки в строке не обнаружено. Для того, чтобы найти последнее вхождение подстроки в строку, можно использовать метод rfind.
Данные любого из основных типов можно преобразовать в символьную строку, для этого используется функция str. Для того, чтобы преобразовать строку в число, можно воспользоваться одной из уже известных нам функций преобразования – int или float. Однако если использовать эту функцию для строки, содержимое которой не является числом, то исполнение программы будет завершено ошибкой несоответствия типов. Поэтому прежде, чем преобразовывать строку в число или другой тип данных, нужно проверить её содержимое. Напишем функцию проверки того, является ли содержимое символьной строки числом.
Назовём нашу функцию IsNumber. Она будет принимать на вход строку, которую нужно проверить. В функцию строка передаётся в виде своей копии. Если строка пуста, то она не является числом, в этом случае функция вернёт значение «ложь». Если строка состоит из одного символа, то для того, чтобы строка являлась числом, этот символ должен быть цифрой. Если это условие выполняется, то функция должна вернуть значение «истина», в противном же случае – «ложь». Если в строке два символа, то для того, чтобы строка являлась числом, это должны быть, соответственно, знак минус и цифра, или же две цифры. Если это условие выполняется, то функция вернёт значение «истина», в противном случае – «ложь». Если в строке больше двух символов, то для того, чтобы она являлась числом, её первый символ должен быть либо знаком минус, либо цифрой, последний же символ должен быть цифрой. Если это условие не выполняется, то функция вернёт значение «ложь». Каждый же символ, начиная с позиции с индексом 1 и заканчивая предпоследним, должен быть либо цифрой, либо точкой. Для проверки этого условия запишем цикл с параметром i, изменяющимся в диапазоне от 1 до индекса предпоследнего символа строки s. В цикле запишем ветвление с условием, что символ строки s[i] не является цифрой или точкой. Если это условие выполняется, то функция вернёт значение «ложь». Далее проверим, не идёт ли в начале строки точка после минуса. Если это условие выполняется, функция вернёт значение «ложь». Осталось лишь проверить количество точек в строке s. Если их больше одной, то строка не является числом. Заведём для этого переменную-счётчик k и присвоим ей значение 0, так как запятые мы ещё не считали. Далее напишем цикл с символьным параметром c, в котором будем перебирать символы строки s. Если на каком-то шаге цикла параметр c стал равен точке, то мы увеличим k на 1. После цикла в переменной k будет храниться количество точек в строке s. И мы вернём истинность высказывания о том, что k < 2.
def IsNumber (s):
if len (s) == 0:
return False
elif len (s) == 1:
return s.isdigit ()
elif len (s) == 2:
return (s[0].isdigit () or s[0] == '-') and s[1].isdigit ()
else:
if not ((s[0].isdigit () or s[0] == '-') and s[len (s) - 1].isdigit ()):
return False
for i in range (1, len (s) - 1):
if not (s[i].isdigit () or s[i] == '.'):
return False
if s[0:2] == '-.':
return False
k = 0
for c in s:
if c == '.':
k = k + 1
return k < 2
Описание функции завершено. Сохраним и протестируем её. Вызовем описанную функцию для целого положительного числа. Функция вернула значение «истина». Вызовем функцию для целого отрицательного числа. Функция снова вернула значение «истина». Теперь вызовем функцию для произвольной символьной строки. Она действительно не является числом. Вызовем функцию для положительного вещественного числа. Функция подтвердила, что это число. Снова вызовем функцию для вещественного отрицательного числа. Было снова возвращено значение «истина». Функция работает правильно. Задача решена.
Продолжим рассматривать инструменты обработки строк. Ранее мы уже познакомились с методами split и join, первый из них делит исходную строку на подстроки по заданной строке-разделителю. Результат этого метода – список подстрок исходной строки. Второй метод, напротив, соединяет список строк в одну строку, вставляя между ними заданную строку-разделитель. Также часто бывает полезен метод replace, который заменяет в исходной строке все вхождения одной подстроки на другую подстроку.

Важным нюансом работы со строками является то, что их можно сравнивать между собой. Например, если сравнить строки «Вася» и «Петя», нам ясно, что по алфавиту «Петя» идёт позже, значит эта строка в нашем примере больше. Так же можно сравнить строки «самосвал» и «самолёт». Первый символ, который в них не совпадает, имеет индекс «четыре». Так как буква «С» идёт по алфавиту после буквы «Л», то строка «самосвал» будет больше.
Как же компьютер сравнивает символьные строки? Для сравнения компьютер последовательно сравнивает коды соответствующих символов в кодовой таблице. Важно при этом понимать, что в кодовой таблице раньше любых букв последовательно следуют цифры. Русские буквы следуют последовательно после английских. При этом заглавные буквы, как русские, так и английские, следуют перед строчными. Буква «ё», как заглавная, так и строчная, следует вне алфавитов. А символ пробела следует раньше цифр. Из того, что строки можно сравнивать между собой, следует то, что их можно сортировать.
Рассмотрим задачу. В строке через запятую перечислены слова. Сформировать из этих слов новую строку, в которой они будут перечислены через пробел и отсортированы по убыванию без учёта регистра.
Начнём написание программы. Вначале с помощью инструкции print выведем на экран запрос на ввод исходной строки. Далее с помощью функции input считаем исходную строку в переменную s. Так как сортировать слова нужно без учёта регистра, приведём строку s к нижнему регистру, используя метод lower. Теперь сформируем список words, состоящий из слов строки s. Для этого к строке s применим метод split, в котором в качестве разделителя укажем подстроку, состоящую из запятой и пробела.
Чтобы отсортировать список words, воспользуемся уже известной нам функцией sorted. Так как элементы списка нужно отсортировать по убыванию, в составе вызова функции sorted присвоим параметру reverse значение «истина». Теперь элементы списка words отсортированы по убыванию. Сформируем из них результирующую строку, которую обозначим r. Для этого используем метод join, в котором в качестве строки-разделителя укажем символ «пробел». С помощью инструкции print с соответствующим поясняющим сообщением выведем на экран результирующую строку.
print ('Исходная строка:', end = ' ')
s = input ()
s = s.lower ()
words = s.split (', ')
words = sorted (words, reverse = True)
r = ' '.join (words)
print ('Результирующая строка:', r)
Сохраним описанный модуль и запустим его на выполнение. В исходной строке перечислим через запятую слова: собака, кот, почтальон и гусь. Программа вывела на экран строку: «собака почтальон кот гусь». В ней слова разделены пробелами и отсортированы по убыванию. Программа работает правильно. Задача решена.
Мы узнали:
· Символьная строка – это набор нумерованных символов, которые хранятся в оперативной памяти компьютера под одним именем и располагаются последовательно друг за другом.
· Для обработки строк в языке Python определён ряд методов и операций.
· Символьные строки можно сравнивать и сортировать.
 0
0 5352
5352

