SQL – структурный язык запросов
Общие положения
Взаимодействие пользователя с СУБД фактически осуществляется при помощи языка SQL. По своей структуре язык делится на три части.
В разделе DDL(определения данных) собраны команды, которые задают структуру тех или иных объектов данных. К ним относятся таблицы, представления, индексы, домены и прочие структурные сущности.
Раздел DML(манипулирование данными) представляет разработчику набор команд, позволяющих манипулировать данными(выборка, добавление, удаление, изменение).
Раздел DCL(управление данными) состоит из средств, которые определяют права доступа к объектам базы данных. Например, разрешает доступ к данным или запрещает его.
Схему принципа использования SQL можно представить следующим образом
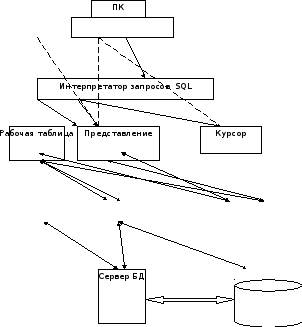
Виртуальная

Реальная
Хранимая
Пользователь передает запрос интерпретатору, который, в свою очередь возвращает представления, таблицу или курсор. Эти объекты находятся на так называемом виртуальном уровне и формируются только по запросу. Но они взаимодействуют с реальным уровнем, т.е. с таблицами БД.
Типы данных SQL/92(Из учебника Хомоненко сделать дополнения к последующему материалу стр. 44. )
Типы данных, используемые в стандартном SQL, можно подразделить на следующие группы:
1.строковые типы;
2. числовые типы;
3. типы для представления даты и времени.
Имеется две основных разновидности таблиц, хранимых в базе данных: традиционная таблица и типизированная таблица. Традиционная таблица определяется как множество столбцов с указанными типами данных. В SQL поддерживаются следующие категории типов данных: точные числовые типы; приближенные числовые типы; типы символьных строк; типы битовых строк; типы даты и времени; типы временных интервалов; булевский тип; типы коллекций; анонимные строчные типы; типы, определяемые пользователем; ссылочные типы.
Типы данных SQL ядра базы данных Microsoft Access — это 13 основных типов данных, определенных ядром базы данных Microsoft Access, и несколько допустимых синонимов, признанных для этих типов данных.
Основные типы данных перечислены в следующей таблице.
| Тип данных | Размер | Описание |
| BINARY | 1 байт на символ | В таком поле могут быть сохранены данные любого типа. Преобразование данных (например, в текст) не производится. От способа ввода данных в бинарное поле зависит способ вывода выходных данных. |
| BIT | 1 байт | Значения «Да» и «Нет», а также поля, содержащие только одно из двух возможных значений. |
| TINYINT | 1 байт | Целое число от 0 до 255. |
| MONEY | 8 байт | Масштабируемое целое число в диапазоне от -922 337 203 685 477,5808 до 922 337 203 685 477,5807. |
| DATETIME (см. DOUBLE) | 8 байт | Даты и время, относящиеся к годам с 100 по 9999. |
| UNIQUEIDENTIFIER | 128 бит | Уникальный идентификационный номер, используемый для удаленного вызова процедур. |
| REAL | 4 байта | Значения обычной точности с плавающей запятой в диапазоне от -3,402823E38 до -1,401298E-45 для отрицательных значений, от 1,401298E-45 до 3,402823E38 для положительных значений и 0. |
| FLOAT | 8 байт | Значения двойной точности с плавающей запятой в диапазоне от -1,79769313486232E308 до -4,94065645841247E-324 для отрицательных значений и от 4,94065645841247E-324 до 1,79769313486232E308 для положительных значений и 0. |
| SMALLINT | 2 байта | Короткое целое число в диапазоне от -32 768 до 32 767 |
| INTEGER | 4 байта | Длинное целое число в диапазоне от -2 147 483 648 до 2 147 483 647 |
| DECIMAL | 17 байт | Точный числовой тип данных, включающий значения от 1028 - 1 до -1028 - 1. Можно определить как точность (1 - 28), так и масштаб (точность определена как 0). Точность и масштаб по умолчанию составляют 18 и 0 соответственно. |
| TEXT | 2 байта на символ (см. «примечание») | От 0 до 214 Гбайт. |
| IMAGE | По требованию | От 0 до 214 Гбайт. Используется для объектов OLE. |
| CHARACTER | 2 байта на символ (см. «примечание») | От 0 до 255 символов. |
Примечание.
Символы в полях, определенных как TEXT (другое название — MEMO) или CHAR (другое название — TEXT(n) с заданной длиной), сохраняются в формате представления символов Юникод. Для сохранения каждого символа в формате Юникода требуется два байта. Для существующих баз данных Microsoft Access, содержащих преимущественно символьные данные, это может привести к почти двукратному увеличению размера базы данных при конвертировании в формат Microsoft Access. Однако представление символов Юникода для многих наборов символов, которые прежде назывались наборами однобайтовых символов (SBCS), можно без труда сжать до одного байта на символ. Если для столбца с типом данных CHAR задать атрибут COMPRESSION, при сохранении данные автоматически будут подвергаться сжатию, а при извлечении из столбца — возвращаться в исходное состояние.
Занятие №1
Введение
SQL является, прежде всего, информационно-логическим языком, предназначенным для описания, изменения и извлечения данных, хранимых в реляционных базах данных. SQL нельзя назвать языком программирования.
Изначально, SQL был основным способом работы пользователя с базой данных и позволял выполнять следующий набор операций:
- создание в базе данных новой таблицы;
- добавление в таблицу новых записей;
- изменение записей;
- удаление записей;
- выборка записей из одной или нескольких таблиц (в соответствии с заданным условием);
а, также, изменение структур таблиц.
Со временем, SQL усложнился — обогатился новыми конструкциями, обеспечил возможность описания и управления новыми хранимыми объектами (например, индексы, представления, триггеры и хранимые процедуры) — и стал приобретать черты, свойственные языкам программирования.
При всех своих изменениях, SQL остаётся единственным механизмом связи между прикладным программным обеспечением и базой данных. В то же время, современные СУБД, а, также, информационные системы, использующие СУБД, предоставляют пользователю развитые средства визуального построения запросов.
Каждое предложение SQL — это запрос или обращение к базе данных, которое приводит к изменению в базе данных. В соответствии с тем, какие изменения происходят в базе данных, различают следующие типы запросов:
- запросы на создание или изменение в базе данных новых или существующих объектов (при этом в запросе описывается тип и структура создаваемого или изменяемого объекта);
- запросы на получение данных;
- запросы на добавление новых данных (записей);
- запросы на удаление данных;
- обращения к СУБД.
Основным объектом хранения реляционной базы данных является таблица, поэтому все SQL-запросы — это операции над таблицами.
В соответствии с этим, запросы делятся на
- запросы, оперирующие самими таблицами (создание и изменение таблиц);
- запросы, оперирующие с отдельными записями (или строками таблиц) или наборами записей.
Каждая таблица описывается в виде перечисления своих полей (столбцов таблицы) с указанием
- типа хранимых в каждом поле значений;
- связей между таблицами (задание первичных и вторичных ключей);
- информации, необходимой для построения индексов.
Запросы первого типа, в свою очередь, делятся на
- запросы, предназначенные для создания в базе данных новых таблиц, и на
- запросы, предназначенные для изменения уже существующих таблиц.
Запросы второго типа оперируют со строками, и их можно разделить на запросы следующего вида:
- вставка новой строки;
- изменение значений полей строки или набора строк;
- удаление строки или набора строк.
Самый главный вид запроса — это запрос, возвращающий (пользователю) некоторый набор строк, с которым можно осуществить одну из трёх операций:
- просмотреть полученный набор;
- изменить все записи набора;
- удалить все записи набора.
Таким образом, использование SQL сводится, по сути, к формированию всевозможных выборок строк и совершению операций над всеми записями, входящими в набор.
Описание
Язык SQL представляет собой совокупность
операторов;
инструкций;
и вычисляемых функций.
Операторы
Согласно общепринятому стилю программирования, операторы (и другие зарезервированные слова) в SQL всегда следует писать прописными буквами .
Операторы SQL делятся на:
1.операторы определения данных (Data Definition Language, DDL)
DDL позволяет пользователю определять новые таблицы и связанные с ними элементы. Большинство коммерческих баз данных SQL имеют собственные расширения в DDL, которые позволяют осуществлять контроль над нестандартныыми, но обычно жизненно важными элементами конкретной системы.
2. операторы манипуляции данными (Data Manipulation Language, DML)
DML является подмножеством языка, используемого для запроса к базам данных, добавления, обновления и удаления данных.
SELECT считывает данные, удовлетворяющие заданным условиям
INSERT добавляет новые данные
UPDATE изменяет существующие данные
DELETE удаляет данные
3.операторы определения доступа к данным (Data Control Language, DCL). DCL отвечает за права доступа к данным и позволяет пользователю контролировать, кто имеет доступ, чтобы просматривать или манипулировать данными в базе данных.
GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом
REVOKE отзывает ранее выданные разрешения
DENY задает запрет, имеющий приоритет над разрешением
4. операторы управления транзакциями (Transaction Control Language, TCL)
COMMIT применяет транзакцию.
ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции.
SAVEPOINT делит транзакцию на более мелкие участки.
1. Определение данных (Data Definition Language, DDL)
Управление объектами базы данных
Объект базы данных — это любой объект, определенный в базе данных и используемый для хранения информации или для обращения к информации. Примера ми объектов базы данных могут служить таблицы, представления и индексы.
Представление- таблица сформированная в результате запроса.
Курсор- своеобразный указатель, используемый для перемещения по наборам записей при их обработке.
Для управления объектами базы данных используется подмножество команд DLL языка SQL.
1.1. Создание, модификация и удаление таблиц
Таблица является основным объектом для хранения информации в реляционной базе данных. При создании таблицы обязательно указываются имена полей, содержащихся в таблице, и типы данных, соответствующие полям. Кроме того, при создании таблицы для полей могут оговариваться ограничительные условия и значения, задаваемые по умолчанию.
Ограничительные условия — это правила, ограничивающие значения величин в поле таблицы базы данных.
Значение по умолчанию — значение, которое автоматически вводится в поле таблицы базы данных при добавлении новой записи, если пользователь не указал значение этого поля.
1.1.1. Оператор CREATE TABLE
Для создания таблицы используется оператор CREATE TABLE. Синтаксис этого оператора имеет следующий вид:
CREATE TABLE имя_таблицы
Пример записи
CREATE TABLE имя_таблицы
({![,…,{!}])
Пример создания таблицы.
Таблица «Студенты» (Файл БД проектирование)
CREATE TABLE Студенты
(ID_Студент INTEGER NOT NULL,
Фамилия CHAR(30) NOT NULL,
Имя CHAR(15) NOT NULL,
Отчество CHAR(20) NOT NULL,
Номер_группы INTEGER NOT NULL,
Адрес CHAR(30),
Телефон CHAR(10),
PRIMARY KEY (ID_Студент)
Задание
Создать таблицы:
Дисциплины.
Учебный_план.
Сводная ведомость.
Кадровый_состав.
Пример для создания и заполнения таблицы
CREATE TABLE Склад
(Товар CHAR(20,
Фирма CHAR(20),
Количество INTEGER ,
Дата_поступления DATETIME)
В созданную таблицу надо занести несколько записей
INSERT INTO Слад VALUES («Болты», «Завод космос», 20, «11.10. 2010»)
INSERT INTO Слад VALUES («Винты», «Уралмаш», 100, «7.11. 2010»)
INSERT INTO Слад VALUES («Гайки», « АПЗ-20», 1000, «15.12. 2010»)
Для извлечения данных запишем
SELECT * FROM Склад
В результате выполнения запроса получим
| Товар | Фирма | Количество | Дата_поступления |
| Болты | Завод космос | 20 | 11.10. 2010 |
| Винты | Уралмаш | 100 | 7.11. 2010 |
| Гайки» | АПЗ-20 | 1000 | 15.12. 2010 |
1.1.2. Оператор ALTER TABLE
В созданной таблице с помощью его можно добавлять и удалять поля таблицы, изменять тип данных полей, добавлять и удалять ограничения.
Синтаксис этого оператора имеет следующий вид:
ALTER TABLE имя_таблицы
Режимы использования:
- добавления столбца;
- удаления столбца;
- модификация столбца;
- работа с ограничениями.
Пример удаления столбца.
ALTER TABLE Студенты
DROP COLUMN Год_поступления
1.1.3. Оператор DROP TABLE
Для удаления таблиц используется оператор DROP TABLE.
Синтаксис этого оператора имеет следующий вид:
DROP TABLE имя_таблицы
1.2. Задание ограничений
Ограничения используются для того, чтобы обеспечить достоверность и непротиворечивость информации в базе данных. Существует достаточно большое количество различного рода ограничений, из которых мы рассмотрим лишь основные:
1.ограничение NOT NULL;
2.ограничение первичного ключа;
3. ограничение UNIQUE;
4. ограничение внешнего ключа;
5. ограничение СНЕСК.
Ограничение NOT NULL
Ограничение NOT NULL может быть установлено для любого поля реляционной таблицы. При наличии этого ограничения запрещается ввод значений NULL в поле, для которого это ограничение установлено.
Ограничение первичного ключа
Так как поля , входящие в состав первичного ключа, не могут принимать значение NULL, то для них обязательным является ограничение NOT NULL.
Ограничение UNIQUE
Ограничение UNIQUE похоже на ограничение первичного ключа, так как при наличии этого ограничения для некоторого поля все значения, содержащиеся в это поле, должны быть уникальными. Однако, в отличие от первичного ключа, ограничение UNIQUE
допускает наличие пустых значений поля (если, конечно, для этого поля не установлено ограничение NOT NULL.
Ограничение UNIQUE задается при создании таблицы с помощью ключевого слова UNIQUE указываемого при описании поля:
Ограничение внешнего ключа
Ограничение внешнего ключа является основным механизмом для поддержания ссылочной целостности базы данных. Поле, определяемое в качестве внешнего ключа используется для ссылки на поле другой таблицы обычно называющееся родительским ключом, а таблица на которую внешний ключ ссылается, называется родительской таблицей (родительски ключ часто является первичным ключом родительской таблицы)
Типы полей внешнего и родительского ключа обязательно должны быть идентичны. А вот имена полей могут быть разными. Однако во избежание путаницы желательно и имена полей для внешнего и родительского ключей задавать одинаковыми.
Внешний ключ не обязательно должен состоять только из одного поля. Подобно первичному ключу внешний ключ может состоять из любого числа полей, которые обрабатываются как единый объект. Поля родительского ключа, на который ссылается составной внешний ключ, должны следовать в том же порядке что и во внешнем ключе.
Когда поле таблицы является внешним ключом, оно определенным образом связано с таблицей на которую этот ключ ссылается. Это фактически означает, что каждое значение внешнего ключа непосредственно привязано к значению в родительском ключе.
Ограничение внешнего ключа FOREIGN KEY задается при создании таблицы.
Ограничение CHECK
Используется для проверки вводимых данных в таблицу.
1.3. Задание значений по умолчанию(DEFAULT)
При этом в поля таблицы при добавлении новой записи значения будут задаваться по умолчанию.
1.4. Создание и удаление индексов(INDEX)
Столбец с уникальным именем.
1.5. Работа с представлениями
Таблицы баз данных. Их содержимое выбирается из других таблиц(представлений)
Оператор CREATE VIEW.
CREATE VIEW имя_представления AS
{ оператор выборки данных}
1.6. Хранимые процедуры
Хранимые процедуры (Stored Procedure) представляют собой группы связанных операторов SQL. Использование хранимых процедур обеспечивает дополнительную гибкость при работе с базой данных, так как выполнить хранимую процедуру обычно гораздо проще, чем последовательность отдельных операторов SQL.
Хранимые процедуры хранятся в базе данных в откомпилированном виде, что обеспечивает более высокую скорость их выполнения.
Хранимые процедуры могут получать входные параметры, возвращать значения приложению и могут быть вызваны явно из приложения или подстановкой вместо имени таблицы в инструкции SELECT.
Основные преимущества, которые дает использование хранимых процедур, заключаются в следующем:
1. хранимые процедуры позволяют вынести часть логики на сервер базы данных. Это ослабляет зависимость базы данных информационной системы от клиентской части;
2. хранимые процедуры обеспечивают модульность проекта: они могут быть общими для клиентских приложений, которые обращаются к одной и той же базе данных, что позволяет избегать повторяющегося кода и уменьшает размер приложений;
3. хранимые процедуры упрощают сопровождение приложений: при обновлении процедур изменения автоматически отражаются во всех приложениях, которые их используют, без необходимости повторной компиляции и сборки;
4. хранимые процедуры повышают эффективность работы информационной системы: они выполняются сервером, а не клиентом, что снижает сетевой трафик;
5. скорость выполнения хранимых процедур выше, чем для последовательности отдельных операторов SQL. Это связано с тем, что хранимые процедуры хранятся на сервере в откомпилированном виде.
Различают два вида хранимых процедур:
1.процедуры выбора, которые приложения могут использовать вместо таблиц или представлений в операторе выборки данных. Процедура выбора должна воз вращать одно или несколько значений, иначе результатом выполнения процедуры будет ошибка;
2. выполняемые процедуры, которые вызываются явно с использованием специального оператора. Выполняемая процедура может не возвращать результата вызываемой программе.
Создание хранимых процедур
Для создания хранимых процедур используется оператор CREATE PROCEDURE. Синтаксис этого оператора сильно зависит от используемой реализации поэтому мы не будем его подробно рассматривать.
Оператор CREATE PROCEDURE определяет новую хранимую процедуру в базе данных. Язык процедур сильно зависит от реализации но, как правило, включает все инструкции для манипулирования данными и ряд расширений, включающих:
-условные операторы;
- различные виды операторов цикла;
- возможности обработки исключительных ситуаций.
Хранимые процедуры состоят из заголовка и тела. Заголовок процедуры содержит:
- имя процедуры, которое должно быть уникальным среди имен процедур и таблиц в базе данных;
- список входных параметров и их типов данных, которые процедура принимает из вызывающей программы (может отсутствовать);
- список выходных параметров и их типов данных, если процедура возвращает значения в вызывающую программу.
Тело процедуры содержит:
-список локальных переменных и их типов данных (если они используются в коде процедуры);
-блок инструкций на языке процедур и триггеров, заключенный между ключевыми словами BEGIN и END. Блок может включать в себя другие блоки, реализуя несколько уровней вложенности.
Выполнение хранимых процедур
Оператор, запускающий хранимую процедуру на выполнение, зависит от типа процедуры. Процедуры выбора выполняются при обращении к ним с помощью оператора выборки данных SELECT.
Для вызова выполняемой процедуры используется оператор EXECUTE.
1.7. Триггеры
Триггеры представляют собой разновидность хранимых процедур. Однако в отличие от хранимых процедур выполнение триггера происходит не в результате явного вызова некоторого оператора SQL, а при выполнении одного из операторов манипулирования данными, вносящими изменения в базу данных. При этом триггеры могут исполняться как до, так и после выполнения оператора манипулирования данными.
Триггеры используются для обеспечения ссылочной целостности данных в базе.
Они предоставляют следующие возможности:
-возможность контроля вводимых данных, чтобы гарантировать, что пользователь ввел в поля таблицы только допустимые значения;
-упрощение сопровождения приложений, так как изменение в триггере автоматически отражается во всех приложениях, которые используют таблицы со связанными с ними триггерами;
-автоматическое документирование изменений таблицы. Приложение может
управлять журналом изменений с помощью триггеров, которые выполняются
всякий раз, когда происходит изменение таблицы.
Создание триггера
Для создания триггера используется оператор CREATE TRIGGER.
Синтаксис этого оператора существенно зависит от используемой реализации SQL.
Так же как и хранимые процедуры, триггеры состоят из заголовка и тела. Заголовок триггера содержит:
-имя триггера, уникальное внутри базы данных;
-имя таблицы, с которой связан триггер;
- инструкции, которые определяют, когда триггер будет выполняться (при выполнении какого оператора манипулирования данными и в какой момент времени — до или после выполнения оператора).
Тело триггера содержит:
- список локальных переменных и их типов данных (если они используются в коде триггера);
- блок инструкций на языке процедур и триггеров, заключенный между ключевыми словами BEGIN и END. Блок может содержать в себе другой блок, реализуя несколько уровней вложенности.
Таким образом, отличие триггера от хранимой процедуры заключается только в заголовке.
Триггер связан с таблицей. Владелец таблицы и любой пользователь, наделенный привилегиями на таблицу, автоматически имеют права выполнять связанные с ней триггеры.
ПРИМЕЧАНИЕ
После создания триггера в него нельзя внести изменения. Чтобы внести изменения в уже созданный триггер, необходимо удалить его и создать заново.
Удаление триггера
Для удаления триггера используется оператор DROP TRIGGER. Синтаксис этого оператора является достаточно общим для различных реализаций.
2. Манипулирование данными(DML)
Для манипулирования данными, хранящимися в базе данных, используется группа операторов SQL выделяемая в качестве отдельного типа команд, называемых языком манипулирования данными (DML). С помощью операторов DML пользователь может загружать в таблицы новые данные, модифицировать и удалять существующие данные.
В языке SQL определены только три основных оператора DML:
- SELECT- извлечение данных:
- INSERT-добавление в таблицу новой информации;
-UPDATE- изменение данных, хранящихся в таблице;
-DELETE- удаление данных из таблицы.
Задание
Сформировать описание таблиц для примера «Учебный план» БД «Сессия».
Заполнить таблицы конкретными данными.
Занятие №2
3.Управление доступом к базе данных
Операторы:
- GRANT(предоставляет пользователю системные и объектные привилегии);
- REVOKE(отменяет предоставленные пользователю системные и объектные привилегии).
4. Язык запросов((DQL)
SELECT (англ., означает «выбрать») — оператор DML языка SQL, возвращающий набор данных (выборку) из базы данных, удовлетворяющих заданному условию.
В большинстве случаев, выборка осуществляется из одной или нескольких таблиц. В последнем случае говорят об операции слияния (JOIN (SQL)). В тех СУБД, где реализованы представления (англ. view) и хранимые процедуры (англ. stored procedure), также возможно получение соответствующих наборов данных.
При формировании запроса SELECT пользователь описывает ожидаемый набор данных: его вид (набор столбцов) и его содержимое (критерий попадания записи в набор, группировка значений, порядок вывода записей и т. п.).
Запрос выполняется следующим образом: сначала извлекаются все записи из таблицы, а затем для каждой записи набора проверяется её соответствие заданному критерию. Если осуществляется слияние из нескольких таблиц, то сначала составляется произведение таблиц, а уже затем из полученного набора отбираются требуемые записи.
Особую роль играет обработка NULL-значений, когда при слиянии, например, двух таблиц — главной (англ. master) и подчинённой (англ. detail) — имеются или отсутствуют соответствия между записями таблиц, участвующих в слиянии. Для решения этой задачи используются механизмы внутреннего (англ. inner) и внешнего (англ. outer) слияния.
4.1.Управление данными
Команда SELECT – извлечения данных, с опциями и предложениями.
Список разделов: SELECT, INTO, FROM, WHERE, GROUP BY, HAVING, UNION, ORDER BY, COMPUTE, FROM, OPTION.
Синтаксис SELECTСписок_выбора[INTOНовая _таблица] FROMИсходная_таблица [WHEREУсловия_отбора] [GROUP BYКлючи_группировки][ HAVINGУсловия_отбора][ ORDER BY Ключи_сортировки[ASC|DESC]]
SELECT-используется для определения столбцов, которые хотим получить в результате запроса.
FROM - используется для определения таблиц, из которых хотим получить столбцы.
GROUP BY- разделяет информацию на группы(группы столбцов).
HAVING – фильтрует групповую информацию.
WHERE – фильтрует строки, возвращаемые условием FROM.
SELECT *- определяет все столбцы после FROM.
DISTINCT – исключает повторяющиеся строки.
Извлечение данных - команда SELECT
Рассмотрим ключевые слова команды SELECT
ALL - Указывает на то, что в результирующем наборе могут появляться повторяющиеся элементы. ALL является значением по умолчанию.
DISTINCT- Указывает, что в результирующем наборе возвращаются только уникальные результаты, т.е. нет повторений.
- TOP n, n- производится отбор n первых строк.
- PERCENT- процент выбранных строк.
*- включено всё.
- WITH TIES - Указание параметра WITH TIES предписывает включить в результат выборки дополнительные строки, имеющие то же значение в столбцах, указанных в разделе ORDER BY, что и последняя строка. Например, если сортировка выполняется по названию штата и количество строк ограничивается с помощью ТОР, то возможна ситуация, что для одного из штатов будет выведена только часть строк. Чтобы вывести все строки, относящиеся к штатам, фигурирующим в выборке, достаточно использовать параметр WITH TIES. Применение WITH TIES допускается только совместно с разделом ORDER BY.
- Для выбора отдельного столбца необходимо явно указать его имя при условии, если она указана в разделе FROM. Если этот столбец есть в двух и более таблицах, то связать название таблицы чрез точку с именем столбца.
- объединение данных из разных столбцов в один столбец.
Задание на 13 09 3013
В своей таблице для двух трёх столбцов примените эти ключевые слова по аналогии
1. SELECT ALL Семестр,Отчетность
FROM Учебный_план
2. SELECT DISTINCT Семестр,Отчетность
FROM Учебный_план
3. SELECT DISTINCT ALL Семестр,Отчетность
FROM Учебный_план
4. SELECT TOP 5 * FROM Студенты
5. SELECT TOP 10 * PERCENT FROM Студенты
6. SELECT TOP 10 * PERCENT FROM Студенты ORDER BY Номер_Группы
7. Выбор отдельного столбца.
SELECT Учебный_план.Наименование,Семестр, Количество_часов
FROM Учебный_план, Дисциплины
8. объединение данных из разных столбцов в один столбец.
SELECT TOP 10 Фамилия + ‘’+ Имя+‘’+ Отчество as ФИО , Номер_Группы FROM Студенты
Поясняющий пример к занятиям
1. DISTINCT
Пример:
SELECT DISTINCT vnum
FROM torder;
Здесь выбираются все различные (без дупликатов) элементы столбца vnum таблицы torder.
Раздел FROM
2. FROM
С помощью FROM сообщают базе данных из каких таблиц выбирать данные.
Пример:
SELECT vnum
FROM torder;
Здесь выбираются все элементы поля vnum таблицы torder.
Пример
SELECT select_list
[INTO new_table]
FROM table_source
[WHERE search_conditions]
[GROUP BY group_by_expression]
[HAVING search_condition]
[ORDER BY order_expression [ASC | DESC] ]
Как отмечалось ранее
Раздел SELECT имеет следующий синтаксис:
SELECT [ ALL | DISTINCT ]
TOP n [PERCENT]
Раздел FROM
table_sourse – источник данных, т.е через запятую перечисляются источники данных с которыми будет работать запрос.
Аргумент table_sourse имеет следующую структуру
:: = table_name [[AS] table_alias] | view_name {{ AS] table_alias] |
Аргумент table_name должен содержать имя таблицы в которой осуществляется выборка данных.
Аргумент view_name указывает имя представления из которого необходимо выбрать данные.
Конструкция join_table имеет следующий синтаксис:
:: = ON
Эта конструкция используется для связывания при выборке из нескольких таблиц. Конструкции описывают связываемые таблицы. Конструкция описывает тип связывания двух таблиц. Исходная таблица указывается слева от конструкции и называет левой таблицей, справа указывается зависимая таблица, которая называется правой таблицей.
Конструкция имеет следующий синтаксис:
:: = [ INNER | (( LEFT | RIGHT | FULL ) [OUTER] ) ]
INNER - При использовании этого типа связи выбираются пары строк для которых имеются строки удовлетворяющие критерию связывания в обеих таблицах. Строки из левой и правой таблиц для которых имеются пары связанной таблицы в результате исключаются. Т.е. включает строки, в которых есть столбцы с совпадающими данными объединяемых таблиц. Используется по умолчанию.
LEFT – в результат будут включены все строки левой таблицы, независимо от того, есть ли для них соответствующая строка в правой таблице или нет. Для соответствующих колонок правой таблицы включенных в результат устанавливается значение NULL.
RIGHT – при использовании этого ключевого слова в результат будут включены все строки правой таблицы независимо от того, есть ли для них соответствующая строка в левой таблице.
FULL – в результат будут включены все строки как правой, так и левой таблицы. Применение ключевого слова FULL можно рассматривать как одновременное использование ключевых слов LEFT и RIGHT.
ON - логическое условие, определяющее условие связывания двух таблиц. В этом условии используются операторы сравнения ,
Примеры на внешнее объединение:
• SELECT * FROM SalesPeople INNER JOIN Customer ON SalesPeople.City=Customer.City
• SELECT * FROM Customer LEFT OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
• SELECT * FROM Customer FULL OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
Картезианские соединения и самообъединения
• Если при включении нескольких таблиц не используются те или иные варианты соединения таблиц, то такие соединения называются картезианскими. Они используются для получения строк из двух различных таблиц. Тогда например, при соединении двух таблиц, каждая из которых содержит по 20 строк, итоговая таблица будет содержать 100 строк – каждая из строк одной таблицы с каждой из строк другой таблицы. SELECT * FROM Customer, Orders.
• Соединения одинаковых таблиц называют самообъединением (self-join).
Примеры ниже
Раздел WHERE
3. WHERE условие
С помощью WHERE ограничивают выбор данных из указанных таблиц.
Проще. Сужается набор строк, которые включаются в результат выборки.
При формировании отбора используются операции сравнения- =,,=,OR,AND,NOT.
WHERE count=5 AND id
Дополнительные логические операторы
1. BETWEEN - нахождение строк, значений содержащих значения, расположенное между двумя значениями
WHERE количество часов_ BETWEEN 50 AND 100
2. IN- Нахождение строк, находящихся в списке значений
WHERE Name IN ('Blade', 'Crown Race', 'Spokes')
where age IN (25,26) – например возраст сотрудников
3. LIKE- Нахождение строк, содержащих значение как часть строки
WHERE Name LIKE '%пр%' возможно надо взять в скобки ('%пр%')
В столбце это могут быть профессора и преподаватели.
По другому- поиск по заданной маске. Маска задается в одинарных кавычках, в качестве спецсимволов используются символы % и _ . Символ % заменяет любое количество любых символов, символ _ заменяет только один символ. Для того чтобы заэкранировать специальные символы используются квадратные скобки [ ]. Например, если нужно найти всех сотрудников, фамилия которых начинается на «Сидо», то в начале знак % не ставим (потому что вначале других символов не будет).
Помимо этого данный раздел может быть использован для связывания таблиц.
Для этого необходимо использовать логический оператор AND.
Везде исправить ошибки
Пример:
SELECT tkunden.knum, tverkauf.vnum, tverkauf.prov
FROM tkunden, tverkauf
WHERE tkunden.vnum=tverkauf.vnum;
Результатом является здесь таблица из строк, состоящих из поля knum таблицы tkunden и полей vnum и prov таблицы tverkauf, где с помощью WHERE указывается как находить строки таблицы tverkauf соответствующие строкам из таблицы tkunden.
Пример:
SELECT tkunden.knum, tverkauf.vnum, tverkauf.prov
FROM tkunden, tverkauf
WHERE tkunden.vnum=tverkauf.vnum order by tkunden.knum asc;
Проверить с помощью своих таблиц.
3.1. Нахождение строки с помощью простого равенства
SELECT ProductID, Name
FROM Product
WHERE Name = “Вася”;
3.2. Нахождение строк с использованием оператора сравнения
SELECT ProductID, Name
FROM Product
WHERE God
3.3. Нахождение строк, содержащих значение, расположенное между двумя значениями
SELECT ProductID, Name, Color
FROM Production
WHERE ProductID BETWEEN 725 AND 734
3.4. Нахождение строк, находящихся в списке значений
SELECT ProductID, Name, Color
FROM Production
WHERE Name IN (“Blade”,”Crown Race”, “Spokes”);
Name – проверяемая величина; через запятую перечисляется набор значений.
3.5. Нахождение строк, которые должны удовлетворять нескольким условиям
SELECT ProductID, Name, Color
FROM Production
WHERE Name LIKE ‘Frame%’
AND Name LIKE (‘HL%’)
AND Color = “Red” ;
LIKE- сравнение символьного типа, а % - шаблон для дополнения символов.
3.6. Связывания таблиц
SELECT Таблица1.Наименование, Таблица1.Семестр, Таблица1.Количество_часов
FROM Учебный_план, Дисциплины
WHERE (Учебный_план.ID_ Дисциплина= Дисциплины.ID_ Дисциплина)AND(Количество_часов 60) AND(Семестр=1);
4.GROUP BY
Осуществляется группировка строк таблиц по определенным правилам. Данный запрос используется для группирования результата одного или нескольких столбцов.
Запросы могут производить обобщенное групповое значение полей точно также как и значение одного поля. Это делается с помощью агрегатных функций. Агрегатные функции производят одиночное значение для всей группы таблицы.
GROUP BY[ALL][,..,n]
Имеется список этих функций:
COUNT - производит номера строк или не-NULL значения полей которые выбрал запрос.
SUM - производит арифметическую сумму всех выбранных значений данного поля.
AVG - производит усреднение всех выбранных значений данного поля.
Функция AVG
AVG([ALL| DISTINCT])
Пример запроса
SELECT Семестр, AVG(количество часов)
FROM Учебный_план
GROUP BY Семестр;
Функция COUNT
COUNT({[ALL| DISTINCT] )]|*})
Она несколько отличается от всех других. Она считает число значений в данном столбце, или число строк в таблице. Когда она считает значения столбца, она используется с DISTINCT чтобы производить счет чисел различных значений в данном поле.
Пример запроса
SELECT Должность, COUNT (*)
FROM Кадровый_ состав
GROUP BY Должность;
В результате возвращается количество строк в каждой группе столбца Должность
Следующий пример
SELECT COUNT ( DISTINCT snum )
FROM Orders;
Функция MAX()
MAX([ALL| DISTINCT] выражение)
Определяет максимальное значение в указанном диапазоне.
Пример запроса
SELECT MAX(Количество_часов),
MAX(Количество_часов/2)
FROM Учебный_план
Или например:
SELECT vnum, MAX(preis)
FROM torder
GROUP BY vnum;
Здесь выбираются в качестве результата все максимальные значения поля preis про найденную группу строк с идентичным значением поля vnum.
Функция MIN()
MIN ([ALL| DISTINCT] )
Пример
SELECT MIN (Количество_часов)
FROM Учебный_план;
Функция SUM ()
SUM ([ALL| DISTINCT] )
Осуществляет суммирование значений в указанном диапазоне
Пример
SELECT Семестр SUM (Количество_часов) AS ‘Нагрузка’
FROM Учебный_план
GROUP BY Семестр;
Произведена группировка строк по семестрам(столбец Семестр) и подсчитана общая нагрузка в часах за каждый семестр
HAVING условие
Синтаксис раздела совпадает с синтаксисом раздела WHERE
Пример:
SELECT vnum, MAX(preis)
FROM torder
GROUP BY vnum
HAVING AVG(preis) 10;
Здесь выбираются все максимальные значения поля preis про найденную группу строк данных с идентичным vnum, удовлетворяющию дополнительному условию, что средняя величина preis больше 10.
ОRDER BY
ORDER BY сортирует строки результирующей таблицы данных. Если ORDER BY используется внутри GROUP BY, то строки сортируются внутри каждой группы результирующих строк. Вместо имен полей могут быть использованы их порядковые номера в списке полей результирующей таблицы. ASC сортирует данные в восходящем порядке, DESC - в обратном.
Предназначен для упорядочения набора данных, возвращаемого после выполнения запроса.
Пример
Сортировка по двум столбцам. Сортируются по семестрам, а затем по количеству часов в порядке убывания.
SELECT TOP 20 Наименование, Семестр, Количество_часов
FROM Учебный_план, Дисциплины
WHERE (Учебный_план.ID_ Дисциплина= Дисциплины.ID_ Дисциплина)
ORDER BY Семестр, Количество_часов DESC;
11.10.2013
Раздел COMPUTE
Выполняются групповые операции операций над содержимым столбцов выборки. Групповые операции задаются с помощью функций агрегирования. Результат агрегирования выводится в отдельной строке после всех данных столбца. Имя агрегированного столбца включается в результат выборки. Ключевое слово BY указывает, что результат вычисления следует сгруппировать. Итак, грегирование выполняется по определенному столбцу результата выборки, причем сами данные остаются неизменными, а результат агрегирования добавляется отдельно. В разделе COMPUTE пользователь указывает функции агрегирования применительно к конкретным столбцам выборки.
Агрегирование с помощью раздела COMPUTE принципиально отличается от агрегирования данных с помощью раздела GROUP BY. В последнем выборка представляет только результат агрегирования, тогда как первый отображает сами данные и только как дополнительный параметр содержит результат агрегирования.
Наиболее простым и наглядным примером использования раздела COMPUTE является вывод суммы по столбцу.
Пример
Вычислить количество дисциплин, читаемых в семестре, и общую сумму часов.
SELECT Наименование, Семестр, Количество_часов
FROM Учебный_план, Дисциплины
WHERE (Учебный_план.ID_ Дисциплина= Дисциплины.ID_ Дисциплина)
AND ( Семестр=2) COMPUTE SUM ( Количество_часов), COUNT (Семестр);
Пример
Составить списки групп и вычислить количество студентов в группе.
SELECT Фамилия, Имя, Отчество, Номер_группы
FROM Студенты
ORDER BY Номер_группы
COMPUTE COUNT (Номер_группы) BY Номер_группы;
В конструкции compute можно использовать агрегирующие функции sum, avg, min, max и count. Функции sum и avg используются только с числовыми типами данных. В отличии от конструкции order by здесь нельзя использовать порядковые номера столбцов списка выбора вместо названия столбцов.
Приведем синтаксис раздела COMPUTE:
COMPUTE
{{ AVG | COUNT | MAX | MIN | STDEV | STDEVP |VAR | VARP | SUM}
(expression)} [,...n]
[BY expression [,...n]]
Рассмотрим назначение и использование параметров раздела:
□ expression. Этот параметр задает выражение, для которого будет применяться функция агрегирования. Выражение может быть любой сложности, однако оно должно содержаться в результате выборки. Это значит, что параметр expression должен быть ничем иным, чем одним из столбцов результата. Если столбец формируется на основе результата вычисления выражения и для него не указан псевдоним, то ссылка на этот столбец в разделе COMPUTE возможна только с помощью выражения, на основе которого вычисляются значения для этого столбца. Если же столбец имеет конкретное имя (например, указанное с помощью псевдонима), то ссылка на этот столбец возможна и по имени.
□ AVG. Возвращает среднее арифметическое.
COUNT. Возвращает количество строк, в которых значение выражения агрегирования не равно NULL.
□ МАХ. Возвращает максимальное значение выражения во всех строках результата.
□ MIN. Возвращает минимальное значение выражения во всех строках результата.
□ STDEV. Возвращает статистическое стандартное отклонение для всех значений выражения.
□ STDEVP. Возвращает смещенную оценку стандартного отклонения (квадратный корень от значения, возвращаемого функцией VARP) ДЛЯ всех значений столбца.
□ VAR. Возвращает несмещенную оценку дисперсии величин для всех значений выражения.
□ VARP. Возвращает смещенную оценку дисперсии (второй центральный момент выборки относительно выборочного среднего) для всех значений выражения.
П SUM. Возвращает сумму всех значений выражения.
□ BY expression. Этот параметр позволяет применять функции агрегирования не ко всему набору данных, а к отдельным группам. Например, если анализируется таблица продаж товаров, то можно выполнить группировку по наименованию товара и подсчитать, какое количество товара было продано и на какую сумму. Параметр BY указывается после выражения (или выражений), по которому осуществляется агрегирование. Использование параметра BY требует обязательного указания раздела ORDER BY. Кроме того, выражений, по которому выполняется группировка, должно быть указано в разделе ORDER BY, Т. е. данные в результате должны быть отсортированы по выражению группировки. Если группировка выполняется по нескольким выражениям и после параметра BY указано более одного выражения, то каждое из этих выражений должно быть также приведено и в разделе ORDER BY. Причем порядок перечисления выражений после параметра BY и в разделе ORDER BY должен совпадать. При этом необязательно, чтобы после параметра BY были указаны все выражения, представленные в разделе ORDER BY. Тем не менее, не допускается пропуск параметров. Например, если используется ORDER BY column1, column2, column3, то все возможные варианты для раздела COMPUTE будут BY column1, column2, column3; BY column1, column2 И BY column1.
Замечание
При наличии раздела COMPUTE не допускается применение параметра DISTINCT, запрещающего включение в результат выборки повторяющихся строк
Раздел UNION
Объединяет результаты выборки, возвращаемые двумя и более запросами.
Чтобы к результатам запросов можно было применить операции объединения, они должны соответствовать следующим требованиям:
- запросы должны возвращать одинаковый набор столбцов при соблюдении одинакового порядка следования их в каждом из запросов;
- типы данных столбцов для всех запросов должны быть одинаковые;
- ни один из результатов не может быть отсортирован ORDER BY , кроме общего результата.
Итак, иногда бывает необходимо в одном запросе объединить данные нескольких таблиц. Речь идет не об объединении столбцов таблиц, а о слиянии строк двух и более таблиц в один массив строк Примером необходимости такого объединения может служить формирование отчета за год, когда данные за каждый месяц находятся в отдельной таблице. Другой пример — анализ данных различных подразделений, когда данные размещаются в разных базах данных и возможно на различных серверах.
Простой пример
Год_2005
Имя Доход
Коля 1000
Алексей 2000
Сергей 5000
Год_2006
Имя Доход
Коля 2000
Алексей 2000
Петр 35000
Запрос
SELECT * FROM Год_2005;
UNION
SELECT * FROM Год_2006;
Получается результирующий набор
Имя Доход
Коля 1000
Алексей 2000
Сергей 5000
Коля 2000
Петр 35000
В результате отобразятся две строки с Колей, так как эти строки различаются значениями в столбцах. Но при этом в результате присутствует лишь одна строка с Алексеем, поскольку значения в столбцах полностью совпадают.
Объединение строк двух таблиц в один массив строк выполняется с помощью раздела UNION, имеющего следующую структуру:
{ | ()} UNION [ALL]
)
[UNION [ALL]
[...n]]
Рассмотрим назначение и использование упомянутых параметров:
П | ()
С помощью этих конструкций указывается запрос, возвращаемые строки которого будут объединены со строками, возвращенными другим запросом. Как видно из синтаксиса, при использовании раздела UNION ДОЛЖНЫ быть
указаны два запроса, возвращающих одинаковое количество столбцов, причем столбцы должны иметь совместимые типы данных и располагаться в одном и том же порядке. Запрос может быть как очень простым (SELECT * FROM ), так и очень сложным с применением всех описанных ранее разделов.
□ ALL
По умолчанию в объединение не допускается вставка повторяющихся строк. То есть, если второй запрос возвращает строку, идентичную одной из строк, образованных первым запросом, то такая строка не будет включена в объединение. Однако с помощью параметра ALL МОЖНО заставить сервер включать в объединение все строки, возвращенные запросами, независимо от того, повторяются они или нет.
С помощью раздела UNION МОЖНО объединять более двух запросов. Для этого после второго запроса достаточно указать ключевое слово UNION И создать третий запрос. Таким же образом можно добавить четвертый запрос, пятый и т д. Общее количество объединяемых запросов может составлять несколько десятков. Однако на практике обычно количество объединяемых запросов не превышает пяти.
Имена столбцов объединения будут соответствовать именам столбцов, возвращаемых первым запросом. Имена столбцов остальных запросов игнорируются. Как уже было сказано, количество столбцов, возвращаемых всеми объединяемыми запросами, должно быть одним и тем же. Кроме того, порядок перечисления этих столбцов в разделе SELECT ВО всех запросах должен быть одинаков. Типы данных столбцов запросов, данные из которых будут объединены в один столбец, должны быть совместимыми. В идеале типы данных должны быть полностью одинаковы, но все же допускаются некоторые расхождения.
При объединении двух символьных столбцов (char, varchar, nchar и nvarchar) разной длины столбец объединения будет иметь тип данных, соответствующий строке большей длины. Также при объединении двоичных данных (binary и varbinary) столбец результата получит тип данных, соответствующий наибольшему из объединяемых столбцов. При объединении столбцов нецелочисленных ТИПОВ данных (money, smallmoney, float, numeric И decimal) столбец результата будет иметь тип данных, соответствующий исходному типу данных с наибольшей точностью. Кроме того, аналогичный результат будет и при объединении целочисленных данных (int, smallint и tinyint) с нецелочисленными — объединение станет иметь нецелочисленный тип данных с наибольшей точностью. Если все соответствующие столбцы исходных запросов запрещают хранение значений NULL, ТО И В соответствующем столбце результата хранение значений NULL будет запрещено. Однако если хоть один из объединяемых столбцов разрешает хранение NULL, ТО И В объединении для соответствующего столбца будет разрешено хранение NULL.
При попытке объединения столбцов с несовместимыми типами данных сервер выдаст сообщение об ошибке.
Выполним следующие запросы
SELECT Фамилия, Имя, Отчество, Должность, Телефон
FROM Кадровый_ состав
WHERE Телефон LIKE ’120%’;
SELECT Фамилия, Имя, Отчество, Телефон
FROM Студенты
WHERE Телефон LIKE ’120%’;
Объединим запросы
SELECT Фамилия, Имя, Отчество, Должность, Телефон
FROM Кадровый_ состав
WHERE Телефон LIKE ’120%’;
UNION
SELECT Фамилия, Имя, Отчество, Новый_столбец=’ Студент’, Телефон
FROM Студенты
WHERE Телефон LIKE ’120%’;
Итоговая таблица имеет столбцы с именем столбцов первого запроса.
Раздел INTO
Синтаксис
INTO имя_новой_таблицы
имя_новой_таблицы – таблица в которую вставляются результаты.
Создается новая таблица, в которую будут вставлены результаты.
Создадим таблицу «Контакты» из таблицы «Студенты»
SELECT ID_ Студент, Адрес, Телефон
INTO Контакты
FROM Студенты;
Остальные столбцы таблицы «Студенты» удалить.
Запрос из таблицы «Контакты»
SELECT *
FROM Контакты
WHERE Телефон LIKE ’120%’;
Столбцы таблицы ID_ Студент, Адрес, Телефон
Для связи с таблицей «Студенты» в таблице «Контакты» построим внешний ключ
ALTER TABLE Контакты
ADD CONSTRAINT FK_Контакт
FOREIGN KEY (ID_ Студент)
REFERENCES Студенты;
Модифицируем запрос для таблицы «Контакты»
SELECT *
FROM Студенты INNER JOIN
Контакты ON
Студенты. ID_ Студент = Контакты. ID_ Студент
WHERE Телефон LIKE ’120%’;
До сюда
10. INSERT -добавление в таблицу новой информации.
Вставка одной и множество строк
- INSERT[INTO][(список_ колонок)] VALUES()
Используемые ключевые слова:
INTO- вставляется между INSERT и именем таблицы куда вставляют данные.
- VALUES- задаются столбцы для вставки данных. Если списка нет, то данные в столбцы заносятся последовательно, начиная с первого.
- DEFULT- данные вставляются по умолчанию.
- INSERT INTO…. SELECT
Конструкция
- INSERT INTO SELECT
10.1. Вставка одной строки с помощью констант.
Рассмотрим Сводная_ ведомость.
Пусть ID_Студент =10, ID_Дисциплина =3. При этом оценка 5.
Команда добавления этих данных в Сводная_ ведомость
INSERT Сводная_ ведомость
VALUES(10,3,5);
Для произвольного порядка и состава столбцов
INSERT INTO Сводная_ ведомость
(ID_Дисциплина , ID_Студент)
VALUES(3,10);
10.2.
Использование INSERT INTO…. SELECT
Примечание.
Прежде чем вставлять данные, необходимо создать таблицу, которая будет содержать интересующие нас данные.
Например для таблицы Студенты (отсюда будем брать данные) создадим таблицу
Студент_2012 (сюда занесем данные).
Тогда
INSERT INTO Студент_2012 SELECT ID_ Студент, Фамилия, Имя, Отчество, Адрес, Телефон
FROM Студенты
WHERE Год_поступления = 2012;
После выполнения этой последовательности команд инициируем запрос на отбор строк из новой таблицы:
SELECT TOP 5 Фамилия, Имя, Отчество
FROM Студент_2012
11. UPDATE- изменение данных, хранящихся в таблице.
Возможный синтаксис
UPDATE SET{={|DEFAULT|NULL}}[,..,n]
{[FROM{}[,..,n]][WHRE]}
SET- отображается список изменяемых столбцов.
Пример
Добавим в таблицу Учебный_план по два часа в столбец Количество_часов для дисциплин 1-го семестра с формой отчетности экзамен.
Посмотрим исходное состояние данных
SELECT *
FROM Учебный_план
WHRE (Отчетность = ‘э’) FND (Семестр =1)
Выполняем изменения
UPDATE Учебный_план SET Количество_часов = Количество_часов + 2
WHRE (Отчетность = ‘э’) FND (Семестр =1)
SELECT *
FROM Учебный_план
WHRE (Отчетность = ‘э’) FND (Семестр =1)
В столбце количество часов мы увидим увеличение значений на 2.
12. DELETE- удаление данных из таблицы.
Возможный синтаксис
DELETE][WHRE]
Удалим из таблицы Учебный_план дисциплины первого семестра с формой отчетности «зачет».
DELETE Учебный_план
WHRE (Отчетность = ‘э’) FND (Семестр =1)
Рассмотрим сначала следующие таблицы
Имя таблицы Имя поля Тип поля Примечание
FAKULTET KOD_F Integer PRIMARY KEY
NAZV_F Char, 30
SPEC KOD_S Integer PRIMARY KEY
KOD_F Integer
NAZV_S Char, 50
STUDENT KOD_STUD Integer PRIMARY KEY
KOD_S Integer
FAM Char, 30
IM Char, 15
OT Char, 15
STIP Decimal, 3
BALL Decimal, 3
Создадим некоторые запросы для данных таблиц(в качестве справки)
SQL SELECT Пример №1
Выбрать студентов, получающих стипендию, равную 150.
SELECT FAM FROM STUDENT WHERE STIP=150;
С помощью данного SQL запроса SELECT выбираются все значения из таблицы STUDENT, поле STIP которых строго равно 150.
SQL SELECT Пример №2
Выбрать студентов, имеющих балл от 82 до 90. Студенты должны быть отсортированы в порядке убывания балла.
SELECT FAM FROM STUDENT WHERE BALL BETWEEN 81 AND 91 ORDER BY BALL DESC;
Как видно из SQL примера, чтобы выбрать студентов, которые имеют балл от 82 до 90, мы используем условие BETWEEN. Чтобы отсортировать в убывающем порядке DESC.
SQL SELECT. Пример №3
Выбрать студентов, фамилии которых начинаются с буквы «А».
SELECT FAM FROM STUDENT WHERE FAM LIKE ‘А%’;
Для того, чтобы выбрать фамилии, начинающиеся с буквы «А», мы используем оператор SQL LIKE для поиска значений по образцу.
SQL SELECT Пример №4
Подсчитать средний балл на каждом факультете.
SELECT NAZV_F As Название, ROUND(AVG(BALL), 2) As СредБалл FROM FAKULTET, SPEC, STUDENT WHERE STUDENT.KOD_S=SPEC.KOD_S AND SPEC.KOD_F=FAKULTET.KOD_F GROUP BY NAZV_F;
Пример запроса SQL SELECT показывает нам использование функции SQL AVG для вычисления среднего значения, ROUND для округления значения, раздела GROUP BY для группировки столбцов.
SQL SELECT. Пример №5.
Подсчитать количество студентов, обучающихся на каждом факультете. Вывести в запросе название факультета, комментарий – «обучается», количество студентов, комментарий «человек».
SELECT NAZV_F||’ обучается ‘||COUNT(STUDENT.BALL)||’ человек’ As CountStudOnFakultet FROM FAKULTET, SPEC, STUDENT WHERE STUDENT.KOD_S=SPEC.KOD_S AND SPEC.KOD_F=FAKULTET.KOD_F GROUP BY NAZV_F;
SQL SELECT. Пример №6.
Упорядочить студентов по факультетам, специальностям, фамилиям.
SELECT NAZV_F, NAZV_S, FAM FROM FAKULTET, SPEC, STUDENT WHERE STUDENT.KOD_S=SPEC.KOD_S AND SPEC.KOD_F=FAKULTET.KOD_F ORDER BY NAZV_F, NAZV_S, FAM;
SQL SELECT. Пример №7.
Определить, кто учится на специальности, к которой относится студент «Асанов».
SELECT FAM FROM STUDENT WHERE STUDENT.KOD_S=(SELECT KOD_S FROM STUDENT WHERE FAM=’Асанов’);
В данном SQL примере мы используем подзапрос SQL SELECT, который возвращает код специальности, на которой учится студент по фамилии Асанов.
SQL SELECT. Пример №8.
Показать, какие специальности встречаются в таблице STUDENT. Дубликаты исключить. Вывести в запросе названия специальностей.
SELECT DISTINCT NAZV_S FROM SPEC, STUDENT WHERE STUDENT.KOD_S=SPEC.KOD_S;
Здесь мы с помощью SQL ограничения DISTINCT выводим только различные значения.
SQL SELECT. Пример №9.
Извлечь из базы данных все данные по сотрудникам, принятым на работу после 01.01.1980 г. в формате “Сотрудник принят на работу ”.
SELECT CONCAT(CONCAT(CONCAT(‘Сотрудник ‘, sname), CONCAT(SUBSTR(fname, 0, 1), SUBSTR(otch, 0, 1))), CONCAT(‘принят на работу ‘, acceptdate)) FROM employees WHERE acceptdate to_date(’01.01.80′,’dd.mm.yyyy’);
В данном SQL SELECT, используя SQL функцию CONCAT мы выводим все поля таблицы в одну строчку. SQL функция to_date возвращает привычное для СУБД значение даты.
SQL SELECT. Пример №10.
Извлечь из базы данных перечень должностей, которые имеют сотрудники следующих отделов: ‘БИОТЕХНОЛОГИЙ’, ‘ИНЖЕНЕРНОЙ ЭКОЛОГИИ’. В запросе использовать названия отделов.
SELECT pname FROM posts, departments, employees WHERE posts.pid = employees.pid AND employees.did = departments.did AND (departments.dname = ‘БИОТЕХНОЛОГИЙ’ OR departments.dname = ‘ИНЖЕНЕРНОЙ ЭКОЛОГИИ’);
Примеры на формирование запросов с заполненными таблицами
Пример №1
| Таблица1 |
| Номер | Фамилия | Имя | Отчество |
| 1 | Чистяков | Сергей | Витальевич |
| 2 | Маринин | Илья | Сергеевич |
| 3 | Новиков | Владимир | Петрович |
| 4 | Стариков | Илья | Игоревич |
| 5 | Емельянов | Сергей | Анатольевич |
|
|
|
|
|
| Таблица1 |
| Номер | Фамилия | Имя | Отчество |
| 1 | Чистяков | Сергей | Витальевич |
| 2 | Маринин | Илья | Сергеевич |
| 3 | Новиков | Владимир | Петрович |
| 4 | Стариков | Илья | Игоревич |
| Запрос1 |
| Номер | Фамилия | Имя | Отчество |
| 2 | Маринин | Илья | Сергеевич |
| 4 | Стариков | Илья | Игоревич |
SELECT Таблица1.Номер, Таблица1.Фамилия, Таблица1.Имя, Таблица1.Отчество
FROM Таблица1
WHERE (((Таблица1.Имя)="Илья"));
Пример № 2
| Запрос1 |
| Номер | Фамилия | Имя | Отчество |
| 1 | Чистяков | Сергей | Витальевич |
| 2 | Маринин | Илья | Сергеевич |
| 4 | Стариков | Илья | Игоревич |
| 5 | Емельянов | Сергей | Анатольевич |
SELECT Таблица1.Номер, Таблица1.Фамилия, Таблица1.Имя, Таблица1.Отчество
FROM Таблица1
WHERE (((Таблица1.Имя)="Илья" Or (Таблица1.Имя)="Сергей"));
Пример №3
| Таблица1 |
| ФИО | Зарплата |
| Новиков А.П. | 7 500,00р. |
| Сергеев И.В. | 8 000,00р. |
SELECT Таблица1.ФИО, Таблица2.Должность, Таблица1.Зарплата
FROM Таблица1 INNER JOIN Таблица2 ON Таблица1.ФИО=Таблица2.ФИО;
| Таблица2 | | ФИО | Должность | | Новиков А.П. | продавец | | Сергеев И.В. | менеджер | Запрос1 |
| ФИО | Должность | Зарплата |
| Новиков А.П. | продавец | 7 500,00р. |
| Сергеев И.В. | менеджер | 8 000,00р. |
Пример №4
| Таблица1 | | ФИО | Зарплата | | Новиков А.П. | 7 500,00р. | | Петров В.А. | 8 000,00р. | | Сергеев И.В. | 17 300,00р. | Таблица2 |
| ФИО | Должность |
| Новиков А.П. | продавец |
| Сергеев И.В. | менеджер |
SELECT Таблица1.ФИО, Таблица2.Должность, Таблица1.Зарплата
FROM Таблица1 LEFT JOIN Таблица2 ON Таблица1.ФИО=Таблица2.ФИО;
| Запрос1 |
| ФИО | Должность | Зарплата |
| Новиков А.П. | продавец | 7 500,00р. |
| Петров В.А. |
| 8 000,00р. |
| Сергеев И.В. | менеджер | 17 300,00р. |
Пример №5
| Таблица1 |
| Наименование | Осталось на складе | Продано |
| Карандаши | 57 | 17 |
| Ручки | 15 | 3 |
| Тетради | 43 | 41 |
SELECT Таблица1.Наименование, Таблица1.[Осталось на складе], Таблица1.Продано, Таблица1![Осталось на складе]+Таблица1!Продано AS Всего
FROM Таблица1;
| Запрос1 |
| Наименование | Осталось на складе | Продано | Всего |
| Карандаши | 57 | 17 | 74 |
| Ручки | 15 | 3 | 18 |
| Тетради | 43 | 41 | 84 |
Пример №6
| Таблица1 | | Товар | Стоимость | Количество на складе | | Карандаш | 3,00р. | 32 | | Краски | 15,00р. | 12 | | Ручка | 7,00р. | 44 | | Тетрадь | 12,00р. | 17 | Запрос1 |
| Sum-Стоимость | Sum-Количество на складе |
| 37,00р. | 105 |
SELECT Sum(Таблица1.Стоимость) AS [Sum-Стоимость], Sum(Таблица1.[Количество на складе]) AS [Sum-Количество на складе]
FROM Таблица1;
Пример №7
| Таблица1 | | ФИО | Зарплата | Должность | | Иванов | 11 000,00р. | менеджер | | Петров | 10 000,00р. | продавец | | Сидоров | 19 000,00р. | директор | Запрос1 |
| ФИО | Зарплата |
| Петров | 10 000,00р. |
| Семенов | 11 000,00р. |
| Сидоров | 19 000,00р. |
UPDATE Таблица1 SET Таблица1.ФИО = [Введите фамилию], Таблица1.Зарплата = [Введите зарплату];
Пример №8
| Таблица1 |
| Сотрудник | Зарплата | Должность |
| Иванов | 14 000,00р. | менеджер |
| Петров | 9 000,00р. | продавец |
| Сидоров | 15 000,00р. | бухгалтер |
DELETE Таблица1.Сотрудник
FROM Таблица1
WHERE (((Таблица1.Сотрудник)=[Введите фамилию]));
| Таблица1 |
| Сотрудник | Зарплата | Должность |
| Иванов | 0,00р. |
|
| Петров | 0,00р. |
|
| Семенов | 0,00р. |
|
| Сидоров | 0,00р. |
|
Пример №9
| Таблица1 |
| Сотрудник | Зарплата | Должность |
| Иванов | 14 000,00р. | бухгалтер |
| Петров | 18 000,00р. | менеджер |
| Сидоров | 19 000,00р. | директор |
INSERT INTO Таблица1 ( Сотрудник, Должность, Зарплата )
SELECT [Введите фамилию] AS Сотрудник, [Введите должность] AS Должность, [Введите зарплату] AS Зарплата
FROM Таблица1;
| Таблица1 |
| Сотрудник | Зарплата | Должность |
| Иванов | 14 000,00р. | бухгалтер |
| Петров | 18 000,00р. | менеджер |
| Семенов |
| учитель |
| Сидоров | 19 000,00р. | директор |
Пример №10
SELECT [Введите ФИО сотрудника] AS Сотрудник, [Введите должность] AS Должность, [Введите зарплату] AS Зарплата INTO Таблица;
| Таблица |
| Сотрудник | Должность | Зарплата |
|
|
|
|
Пример №11
| Таблица1 |
| Код | Фамилия | Имя | Отчество | Подчиненные |
| 1 | Пронин | Виктор | Иванович |
|
| 2 | Разин | Виталий | Георгиевич | Шолохов В.А. |
| 3 | Степной | Алексей | Петрович |
|
| 4 | Похомов | Андрей | Сергеевич | Дядько В.П. |
SELECT Таблица1.Код, Таблица1.Фамилия, Таблица1.Имя, Таблица1.Отчество, Таблица1.Подчиненные
FROM Таблица1
WHERE (((Таблица1!Подчиненные)"nil"));
| Запрос1 |
| Код | Фамилия | Имя | Отчество | Подчиненные |
| 2 | Разин | Виталий | Георгиевич | Шолохов В.А. |
| 4 | Похомов | Андрей | Сергеевич | Дядько В.П. |
Пример №12
| Таблица1 |
| Код продукта | Наименование | Цена | Категория |
| 1 | карандаш 1 | 30,00р. | 1 |
| 2 | карандаш 2 | 150,00р. | 1 |
| 3 | карандаш 3 | 7,00р. | 1 |
| 4 | ручка 1 | 5,00р. | 2 |
| 5 | ручка 2 | 8,00р. | 2 |
| 6 | ручка 3 | 2,00р. | 2 |
| 7 | карандаш 4 | 170,00р. | 1 |
SELECT Таблица1.Наименование, Таблица1.Цена, Таблица1.Категория, [Выборка максимального].[Max-Цена], [Выборка минимального].[Min-Цена]
FROM (Таблица1 INNER JOIN [Выборка максимального] ON Таблица1.Категория=[Выборка максимального].Категория) INNER JOIN [Выборка минимального] ON Таблица1.Категория=[Выборка минимального].Категория
GROUP BY Таблица1.Наименование, Таблица1.Цена, Таблица1.Категория, [Выборка максимального].[Max-Цена], [Выборка минимального].[Min-Цена], [Выборка максимального].Категория, [Выборка минимального].Категория;
| Запрос1 |
| Наименование | Цена | Категория | Max-Цена | Min-Цена |
| карандаш 1 | 30,00р. | 1 | 170,00р. | 7,00р. |
| карандаш 2 | 150,00р. | 1 | 170,00р. | 7,00р. |
| карандаш 3 | 7,00р. | 1 | 170,00р. | 7,00р. |
| карандаш 4 | 170,00р. | 1 | 170,00р. | 7,00р. |
| ручка 1 | 5,00р. | 2 | 8,00р. | 2,00р. |
| ручка 2 | 8,00р. | 2 | 8,00р. | 2,00р. |
| ручка 3 | 2,00р. | 2 | 8,00р. | 2,00р. |
Пример №13
| Таблица1 | | Поставщик | Город | | ГиК | Тамбов | | ГОК | Железногорск | | Металлторг | Рыльск | | МЭБИК | Железногорск | | Мясторг | Курск | | Рыбторг | Курск | | Рыльский ЛВЗ | Рыльск | Запрос1 |
| Город |
| Железногорск |
| Курск |
| Рыльск |
| Тамбов |
SELECT Таблица1.Город
FROM Таблица1
GROUP BY Таблица1.Город;
Пример №14
| Таблица1 |
| Номер заказа | Наименование | Цена | Количество | Дата |
| 1 | Карандаш | 15,00р. | 2 | 08.08.2007 |
| 2 | Ручка | 20,00р. | 3 | 09.09.2007 |
| 3 | Пенал | 35,00р. | 1 | 11.12.2007 |
| 4 | Кисть | 13,00р. | 2 | 12.03.2008 |
| 5 | Краски | 11,00р. | 3 | 10.02.2008 |
| 7 | Линейка | 3,00р. | 1 | 11.01.2008 |
SELECT Last(Таблица1!Цена*Таблица1!Количество) AS Сумма
FROM Таблица1;
Пример №15
| Таблица1 | | Номер заказа | Фамилия | | 532 | Стариков К.Г. | | 678 | Хомченко В.А. | | 890 | Новиков А.П. | Запрос1 |
| Номер заказа | Фамилия |
| 532 | Стариков К.Г. |
| 678 | Хомченко В.А. |
| 890 | Новиков А.П. |
SELECT Таблица1.[Номер заказа], Таблица1.Фамилия
FROM Таблица1
ORDER BY Таблица1.[Номер заказа];
Пример №16
| Таблица1 | | Код | Номер продукта | Количество | | 1 | 1 | 5 | | 2 | 1 | 3 | | 3 | 1 | 8 | | 4 | 2 | 3 | | 5 | 2 | 3 | | 6 | 3 | 6 | | 7 | 2 | 2 | Запрос1 |
| Номер продукта | Sum-Количество |
| 1 | 16 |
| 2 | 8 |
| 3 | 6 |
SELECT Таблица1.[Номер продукта], Sum(Таблица1.Количество) AS [Sum-Количество]
FROM Таблица1
GROUP BY Таблица1.[Номер продукта];
Пример №17
| Таблица1 | | Код | Покупатель | Дата покупки | | 1 | Пронский В.Г. | 01.01.1996 | | 2 | Шариков А.П. | 06.01.1997 | | 3 | Кнопов С.Н. | 08.01.1997 | | 4 | Стариков С.Г. | 09.02.1997 | Запрос1 |
| Покупатель | Дата покупки |
| Шариков А.П. | 06.01.1997 |
| Кнопов С.Н. | 08.01.1997 |
SELECT Таблица1.Покупатель, Таблица1.[Дата покупки]
FROM Таблица1
WHERE (((Таблица1.[Дата покупки]) Between #1/1/1997# And #1/31/1997#));
1.2. INSERT -добавление в таблицу новой информации.
Вставка одной строки
INSERT[INTO][(список_ колонок)] VALUES()
1.3. UPDATE- изменение данных, хранящихся в таблице.
Возможный синтаксис
UPDATE SET{={|DEFAULT|NULL}}[,..,n]
{[FROM{}[,..,n]][WHRE]}
1.4. DELETE- удаление данных из таблицы.
Возможный синтаксис
DELETE][WHRE]
Задание
Изучить синтаксис команды SELECT.
Набрать в Access таблицы примеров и проверить правильность выполнения запросов.
Поясняющий материал(Справочно)
Пример. База данных поставщиков и деталей. Таблицы SUPPLIER, SELLS, PART
SUPPLIER SELLS
SNO | SNAME | CITY SNO | PNO
1 | Smith | London 1 | 1
2 | Jones | Paris 1 | 2
3 | Adams ! Vienna 2 | 4
4 | Blake | Rome 3 | 1
3 | 3
4 | 2
PART 4 | 3
PNO | PNAME | PRICE 4 | 4
1 | Screw | 10
2 | Nut | 8
3 | Bolt | 15
4 | Cam | 25
Создание таблицы
CREATE TABLE SUPPLIER
(SNO INTEGER,
SNAME VARCHAR(20),
CITY VARCHAR(20));
CREATE TABLE PART
(PNO INTEGER,
PNAME VARCHAR(20),
PRICE DECIMAL(4 , 2));
CREATE TABLE SELLS
(SNO INTEGER,
PNO INTEGER);
Создание индекса
Для создания индекса с именем I по атрибуту SNAME отношения SUPPLIER используем следующее выражение:
CREATE INDEX I
ON SUPPLIER (SNAME);
Созданный индекс обслуживается автоматически, т.е. при вставке ново кортежа в отношение SUPPLIER, индекс I будет перестроен. Заметим, что пользователь может ощутить изменения в при существовании индекса только по увеличению скорости.
Создание представлений
Представление можно рассматривать как виртуальную таблицу, т.е. таблицу, которая в базе данных не существует физически, но для пользователя она как-бы там есть. По сравнению, если мы говорим о базовой таблице, то мы имеем в виду таблицу, физически хранящую каждую строку где-то на физическом носителе.
Представления не имеют своих собственных, физически самостоятельных, различимых хранящихся данных. Вместо этого, система хранит определение представления (т.е. правила о доступе к физически хранящимся базовым таблицам в порядке претворения их в представление) где-то в системных каталогах.
Для определения представлений в SQL используется команда CREATE VIEW
CREATE VIEW London_Suppliers
AS SELECT S.SNAME, P.PNAME
FROM SUPPLIER S, PART P, SELLS SE
WHERE S.SNO = SE.SNO AND
P.PNO = SE.PNO AND
S.CITY = 'London';
Теперь мы можем использовать это виртуальное отношение London_Suppliers как если бы оно было ещё одной базовой таблицей:
SELECT *
FROM London_Suppliers
WHERE P.PNAME = 'Screw';
которое возвращает следующую таблицу:
SNAME | PNAME
-------+-------
Smith | Screw
Для вычисления этого результата система базы данных в начале выполняет скрытый доступ к базовым таблицам SUPPLIER, SELLS и PART. Это делается с помощью выполнения заданных запросов в определении представления к этим базовым таблицам. После, это дополнительное определение (заданное в запросе к представлению) можно использовать для получения результирующей таблицы.
Уничтожение объекта
Для уничтожения таблицы (включая все кортежи, хранящиеся в этой таблице) используется команда DROP TABLE:
Для уничтожения таблицы SUPPLIER используется следующее выражение:
DROP TABLE SUPPLIER;
Команда DROP INDEX используется для уничтожения индекса:
DROP INDEX index_name;
Наконец, для уничтожения заданного представления используется команда DROP VIEW:
DROP VIEW view_name;
Манипулирование данными
Insert Into
После создания таблицы (смотри Создание таблицы), её можно заполнять кортежами с помощью команды INSERT INTO.
Чтобы вставить первый кортеж в отношение SUPPLIER (из База данных поставщиков и деталей) мы используем следующее выражение:
INSERT INTO SUPPLIER (SNO, SNAME, CITY)
VALUES (1, 'Smith', 'London');
Чтобы вставить первый кортеж в отношение SELLS используется:
INSERT INTO SELLS (SNO, PNO)
VALUES (1, 1);
Обновление
Для изменения одного или более значений атрибутов кортежей в отношении используется команда UPDATE.
Чтобы изменить значение атрибута PRICE детали 'Screw' в отношении PART используется:
UPDATE PART
SET PRICE = 15
WHERE PNAME = 'Screw';
Новое значение атрибута PRICE кортежа, чьё имя равно 'Screw' теперь стало 15.
Удаление
Для удаления кортежа из отдельной таблицы используется команда DELETE FROM.
Чтобы удалить поставщика называемого 'Smith', из таблицы SUPPLIER используем следующее выражение:
DELETE FROM SUPPLIER
WHERE SNAME = 'Smith';
Выборка
Оператор SELECT
Простые выборки
Простой ограничивающий запрос
Получить все кортежи из таблицы PART, где атрибут PRICE больше 10:
SELECT * FROM PART
WHERE PRICE 10;
Получаемая таблица:
PNO | PNAME | PRICE
-----+---------+--------
3 | Bolt | 15
4 | Cam | 25
Использовав "*" в операторе SELECT, получаем все атрибуты из таблицы. Если мы хотим получить только атрибуты PNAME и PRICE из таблицы PART, то используем следующее выражение:
SELECT PNAME, PRICE
FROM PART
WHERE PRICE 10;
В этом случае получим:
PNAME | PRICE
--------+--------
Bolt | 15
Cam | 25
Заметим, что SQL SELECT соответствует "проекции" в реляционной алгебре, а не "выборке" (подробней смотри Реляционная алгебра).
Ограничения в операторе WHERE могут также быть логически соединены с помощью ключевых слов OR, AND, и NOT:
SELECT PNAME, PRICE
FROM PART
WHERE PNAME = 'Bolt' AND
(PRICE = 0 OR PRICE
приведёт к результату:
PNAME | PRICE
--------+--------
Bolt | 15
Арифметические операции могут использоваться в списке объектов и операторе WHERE. Например, если нам надо знать сколько будут стоить две штуки одной детали, то используем следующий запрос:
SELECT PNAME, PRICE * 2 AS DOUBLE
FROM PART
WHERE PRICE * 2
и мы получим:
PNAME | DOUBLE
--------+---------
Screw | 20
Nut | 16
Bolt | 30
Заметим, что слово DOUBLE после ключевого слова AS - это новый заголовок второго столбца. Эта техника может быть использована для любого элемента списка объектов, для того чтобы задать новый заголовок столбцу результата. Этот новый заголовок часто называют псевдонимом. Псевдонимы не могут просто использоваться в запросе.
Соединения
Для объединения трёх таблиц SUPPLIER, PART и SELLS по их общим атрибутам, мы формулируем следующее выражение:
SELECT S.SNAME, P.PNAME
FROM SUPPLIER S, PART P, SELLS SE
WHERE S.SNO = SE.SNO AND
P.PNO = SE.PNO;
и получаем следующую таблицу в качестве результата:
SNAME | PNAME
-------+-------
Smith | Screw
Smith | Nut
Jones | Cam
Adams | Screw
Adams | Bolt
Blake | Nut
Blake | Bolt
Blake | Cam
В операторе FROM мы вводим псевдоним имени для каждого отношения, так как в отношениях есть общие названия атрибутов (SNO и PNO). Теперь мы можем различить общие имена атрибутов, просто предварив имя атрибута псевдонимом с точкой. Соединение вычисляется тем же путём, как показано во внутреннем соединением. Во-первых, определяется декартово произведение SUPPLIER × PART × SELLS . Потом выбираются только те кортежи, которые удовлетворяют условиям, заданным в операторе WHERE (т.е. где общие именованные атрибуты равны). Наконец, убираются все колонки кроме S.SNAME и P.PNAME.
Итоговые операторы
SQL снабжён итоговыми операторами (например AVG, COUNT, SUM, MIN, MAX), которые принимают название атрибута в качестве аргумента. Значение итогового оператора высчитывается из всех значений заданного атрибута(столбца) всей таблицы. Если в запросе указана группа, то вычисления выполняются только над значениями группы (смотри следующий раздел).
Итоги
Если мы хотим узнать среднюю стоимость всех деталей в таблице PART, то используем следующий запрос:
SELECT AVG(PRICE) AS AVG_PRICE
FROM PART;
Результат:
AVG_PRICE
-----------
14.5
Если мы хотим узнать количество деталей, хранящихся в таблице PART, то используем выражение:
SELECT COUNT(PNO)
FROM PART;
и получим:
COUNT
-------
4
Итоги по группам
SQL позволяет разбить кортежи таблицы на группы. После этого итоговые операторы, описанные выше, могут применяться к группам (т.е. значение итогового оператора вычисляется не из всех значений указанного столбца, а над всеми значениями группы. Таким образом, итоговый оператор вычисляет индивидуально для каждой группы.)
Разбиение кортежей на группы выполняется с помощью ключевых слов GROUP BY и следующим за ними списком атрибутов, которые определяют группы. Если мы имеем GROUP BY A1, ⃛, Ak мы разделяем отношение на группы так, что два кортежа будут в одной группе, если у них соответствуют все атрибуты A1, ⃛, Ak.
Итоги
Если мы хотим узнать сколько деталей продаёт каждый поставщик, то мы так сформулируем запрос:
SELECT S.SNO, S.SNAME, COUNT(SE.PNO)
FROM SUPPLIER S, SELLS SE
WHERE S.SNO = SE.SNO
GROUP BY S.SNO, S.SNAME;
и получим:
SNO | SNAME | COUNT
-----+-------+-------
1 | Smith | 2
2 | Jones | 1
3 | Adams | 2
4 | Blake | 3
Теперь давайте посмотрим что здесь происходит. Во-первых, соединяются таблицы SUPPLIER и SELLS:
S.SNO | S.SNAME | SE.PNO
-------+---------+--------
1 | Smith | 1
1 | Smith | 2
2 | Jones | 4
3 | Adams | 1
3 | Adams | 3
4 | Blake | 2
4 | Blake | 3
4 | Blake | 4
Затем, мы разбиваем кортежи на группы, помещая все кортежи вместе, у которых соответствуют оба атрибута S.SNO и S.SNAME:
S.SNO | S.SNAME | SE.PNO
-------+---------+--------
1 | Smith | 12
--------------------------
2 | Jones | 4
--------------------------
3 | Adams | 13
--------------------------
4 | Blake | 234
В нашем примере мы получили четыре группы и теперь мы можем применить итоговый оператор COUNT для каждой группы для получения итогового результата запроса, данного выше.
Заметим, что для получения результата запроса, использующего GROUP BY и итоговых операторов, атрибуты сгруппированных значений должны также быть в списке объектов. Все остальные атрибуты, которых нет в выражении GROUP BY, могут быть выбраны при использовании итоговых функций. С другой стороны ты можешь не использовать итоговые функции на атрибутах, имеющихся в выражении GROUP BY.
Having
Оператор HAVING выполняет ту же работу что и оператор WHERE, но принимает к рассмотрению только те группы, которые удовлетворяют определению оператора HAVING. Выражения в операторе HAVING должны вызывать итоговые функции. Каждое выражение, использующее только простые атрибуты, принадлежат оператору WHERE. С другой стороны каждое выражение вызывающее итоговую функцию должно помещаться в оператор HAVING.
Having
Если нас интересуют поставщики, продающие более одной детали, используем запрос:
SELECT S.SNO, S.SNAME, COUNT(SE.PNO)
FROM SUPPLIER S, SELLS SE
WHERE S.SNO = SE.SNO
GROUP BY S.SNO, S.SNAME
HAVING COUNT(SE.PNO) 1;
и получим:
SNO | SNAME | COUNT
-----+-------+-------
1 | Smith | 2
3 | Adams | 2
4 | Blake | 3
Подзапросы
В операторах WHERE и HAVING используются подзапросы (вложенные выборки), которые разрешены в любом месте, где ожидается значение. В этом случае значение должно быть получено предварительно подсчитав подзапрос. Использование подзапросов увеличивает выражающую мощность SQL.
Вложенная выборка
Если мы хотим узнать все детали, имеющие цену больше чем деталь 'Screw', то используем запрос:
SELECT *
FROM PART
WHERE PRICE (SELECT PRICE FROM PART
WHERE PNAME='Screw');
Результат:
PNO | PNAME | PRICE
-----+---------+--------
3 | Bolt | 15
4 | Cam | 25
Если мы посмотрим на запрос выше, то увидим ключевое слово SELECT два раза. Первый начинает запрос - мы будем называть его внешним запросом SELECT - и второй в операторе WHERE, который начинает вложенный запрос - мы будем называть его внутренним запросом SELECT. Для каждого кортежа внешнего SELECT внутренний SELECT необходимо вычислить. После каждого вычисления мы узнаём цену кортежа с названием 'Screw' и мы можем проверить выше ли цена из текущего кортежа.
Если мы хотим узнать поставщиков, которые ничего не продают (например, чтобы удалить этих поставщиков из базы данных) используем:
SELECT *
FROM SUPPLIER S
WHERE NOT EXISTS
(SELECT * FROM SELLS SE
WHERE SE.SNO = S.SNO);
В нашем примере результат будет пустым, потому что каждый поставщик продаёт хотя бы одну деталь. Заметим, что мы использовали S.SNO из внешнего SELECT внутри оператора WHERE в внутреннем SELECT. Как описывалось выше подзапрос вычисляется для каждого кортежа из внешнего запроса т.е. значение для S.SNO всегда берётся из текущего кортежа внешнего SELECT.
Объединение, пересечение, исключение
Эти операции вычисляют объединение, пересечение и теоретико-множественное вычитание кортежей из двух подзапросов.
Объединение, пересечение, исключение
Следующий запрос - пример для UNION(объединение):
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNAME = 'Jones'
UNION
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNAME = 'Adams';
даёт результат:
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
3 | Adams | Vienna
Вот пример для INTERSECT(пересечение):
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO 1
INTERSECT
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO 2;
даёт результат:
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
Возвращаются только те кортежи, которые есть в обоих частях запроса
и имеют $SNO=2$.
Наконец, пример для EXCEPT(исключение):
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO 1
EXCEPT
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO 3;
даёт результат:
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
3 | Adams | Vienna
Задание на самостоятельную работу
1. INSERT - вставка строк в таблицу.
Проверить правильность использования операторов манипулирования данными. Пусть имеются такого типа таблицы
| Номер поставщика | Наименование поставщика | Город поставщика |
| 1 | Иванов | Уфа |
| 2 | Петров | Москва |
| 3 | Сидоров | Москва |
| 4 | Сидоров | Челябинск |
Пример 1.Выбрать все данные из таблицы поставщиков.
SELECT *
FROM P;
В результате получим новую таблицу, содержащую полную копию данных из исходной таблицы P.
Пример 2.
Вставка в таблицу нескольких строк, выбранных из другой таблицы (в таблицу TMP_TABLE вставляются данные о поставщиках из таблицы P, имеющие номера, большие 2):
INSERT INTO
TMP_TABLE (PNUM, PNAME)
SELECT PNUM, PNAME
FROM P
WHERE P.PNUM2;
2. UPDATE - обновление строк в таблице
Пример 3. Обновление нескольких строк в таблице:
UPDATE P
SET PNAME = "Пушников"
WHERE P.PNUM = 1;
3. DELETE - удаление строк в таблице
Пример 4. Удаление нескольких строк в таблице:
DELETE FROM P
WHERE P.PNUM = 1;
Пример 5. Удаление всех строк в таблице:
DELETE FROM P;
4. Примеры использования оператора SELECT
Пример 6. Выбрать все данные из таблицы поставщиков
SELECT *
FROM P;
В результате получим новую таблицу, содержащую полную копию данных из исходной таблицы P.
Пример 7. Выбрать все строки из таблицы поставщиков, удовлетворяющих некоторому условию (ключевое слово WHERE…):
SELECT *
FROM P
WHERE P.PNUM 2;
В качестве условия в разделе WHERE можно использовать сложные логические выражения, использующие поля таблиц, константы, сравнения (,
Пример 8. Выбрать некоторые колонки из исходной таблицы (указание списка отбираемых колонок):
SELECT P.NAME
FROM P;
В результате получим таблицу с одной колонкой, содержащую все наименования поставщиков.
Если в исходной таблице присутствовало несколько поставщиков с разными номерами, но одинаковыми наименованиями, то в результатирующей таблице будут строки с повторениями - дубликаты строк автоматически не отбрасываются.
Пример 9. Выбрать некоторые колонки из исходной таблицы, удалив из результата повторяющиеся строки (ключевое слово DISTINCT):
SELECT DISTINCT P.NAME
FROM P;
Использование ключевого слова DISTINCT приводит к тому, что в результатирующей таблице будут удалены все повторяющиеся строки.
Пример 10. Использование скалярных выражений и переименований колонок в запросах (ключевое слово AS…):
SELECT
TOVAR.TNAME,
TOVAR.KOL,
TOVAR.PRICE,
"=" AS EQU,
TOVAR.KOL*TOVAR.PRICE AS SUMMA
FROM TOVAR;
В результате получим таблицу с колонками, которых не было в исходной таблице TOVAR
TNAME KOL PRICE EQU SUMMA
Болт 10 100 = 1000
Гайка 20 200 = 4000
Винт 30 300 = 9000
Пример 11.Упорядочение результатов запроса (ключевое слово ORDER BY…):
SELECT
PD.PNUM,
PD.DNUM,
PD.VOLUME
FROM PD
ORDER BY DNUM;
В результате получим следующую таблицу, упорядоченную по полю DNUM:
PNUM DNUM VOLUME
1 1 100
2 1 150
3 1 1000
1 2 200
2 2 250
1 3 300
Пример 12. Упорядочение результатов запроса по нескольким полям с возрастанием или убыванием (ключевые слова ASC, DESC):
SELECT
PD.PNUM,
PD.DNUM,
PD.VOLUME
FROM PD
ORDER BY
DNUM ASC,
VOLUME DESC;
В результате получим таблицу, в которой строки идут в порядке возрастания значения поля DNUM, а строки, с одинаковым значением DNUM идут в порядке убывания значения поля VOLUME:
PNUM DNUM VOLUME
3 1 1000
2 1 150
1 1 100
2 2 250
1 2 200
1 3 300
Если явно не указаны ключевые слова ASC или DESC, то по умолчанию принимается упорядочение по возрастанию (ASC).
Отбор данных из нескольких таблиц
Пример 13. Естественное соединение таблиц (способ 1 - явное указание условий соединения):
SELECT
P.PNUM,
P.PNAME,
PD.DNUM,
PD.VOLUME
FROM P, PD
WHERE P.PNUM = PD.PNUM;
В результате получим новую таблицу, в которой строки с данными о поставщиках соединены со строками с данными о поставках деталей:
PNUM PNAME DNUM VOLUME
1 Иванов 1 100
1 Иванов 2 200
1 Иванов 3 300
2 Петров 1 150
2 Петров 2 250
3 Сидоров 1 1000
Соединяемые таблицы перечислены в разделе FROM оператора, условие соединения приведено в разделе WHERE. Раздел WHERE, помимо условия соединения таблиц, может также содержать и условия отбора строк.
Пример 14. Естественное соединение таблиц (способ 2 - ключевые слова JOIN… USING…):
SELECT
P.PNUM,
P.PNAME,
PD.DNUM,
PD.VOLUME
FROM P JOIN PD USING PNUM;
Замечание. Ключевое слово USING позволяет явно указать, по каким из общих колонок таблиц будет производиться соединение.
Пример 15. Естественное соединение таблиц (способ 3 - ключевое слово NATURAL JOIN):
SELECT
P.PNUM,
P.PNAME,
PD.DNUM,
PD.VOLUME
FROM P NATURAL JOIN PD;
Замечание. В разделе FROM не указано, по каким полям производится соединение. NATURAL JOIN автоматически соединяет по всем одинаковым полям в таблицах.
Пример 16. Естественное соединение трех таблиц:
SELECT
P.PNAME,
D.DNAME,
PD.VOLUME
FROM
P NATURAL JOIN PD NATURAL JOIN D;
В результате получим следующую таблицу:
PNAME DNAME VOLUME
Иванов Болт 100
Иванов Гайка 200
Иванов Винт 300
Петров Болт 150
Петров Гайка 250
Сидоров Болт 1000
Пример 17. Прямое произведение таблиц:
SELECT
P.PNUM,
P.PNAME,
D.DNUM,
D.DNAME
FROM P, D;
В результате получим следующую таблицу:
PNUM P NAME DNUM DNAME
1 Иванов 1 Болт
1 Иванов 2 Гайка
1 Иванов 3 Винт
2 Петров 1 Болт
2 Петров 2 Гайка
2 Петров 3 Винт
3 Сидоров 1 Болт
3 Сидоров 2 Гайка
3 Сидоров 3 Винт
Т.к. не указано условие соединения таблиц, то каждая строка первой таблицы соединится с каждой строкой второй таблицы.
Пример 18. Соединение таблиц по произвольному условию. Рассмотрим таблицы поставщиков и деталей, которыми присвоен некоторый статус.
Таблица 1 Отношение P (Поставщики)
PNUM PNAME PSTATUS
1 Иванов 4
2 Петров 1
3 Сидоров 2
Таблица 2 Отношение D (Детали)
DNUM DNAME DSTATUS
1 Болт 3
2 Гайка 2
3 Винт 1
Ответ на вопрос "какие поставщики имеют право поставлять какие детали?" дает следующий запрос:
SELECT
P.PNUM,
P.PNAME,
P.PSTATUS,
D.DNUM,
D.DNAME,
D.DSTATUS
FROM P, D
WHERE P.PSTATUS = D.DSTATUS;
В результате получим следующую таблицу:
PNUM PNAME PSTATUS DNUM DNAME DSTATUS
1 Иванов 4 1 Болт 3
1 Иванов 4 2 Гайка 2
1 Иванов 4 3 Винт 1
2 Петров 1 3 Винт 1
3 Сидоров 2 2 Гайка 2
3 Сидоров 2 3 Винт 1
Использование агрегатных функций в запросах
Пример 20. Получить общее количество поставщиков (ключевое слово COUNT):
SELECT COUNT(*) AS N
FROM P;
В результате получим таблицу с одним столбцом и одной строкой, содержащей количество строк из таблицы P:
N
3
Пример 21. Получить общее, максимальное, минимальное и среднее количества поставляемых деталей (ключевые слова SUM, MAX, MIN, AVG):
SELECT
SUM(PD.VOLUME) AS SM,
MAX(PD.VOLUME) AS MX,
MIN(PD.VOLUME) AS MN,
AVG(PD.VOLUME) AS AV
FROM PD;
В результате получим следующую таблицу с одной строкой:
SM MX MN AV
2000 1000 100 333.33333333
Использование агрегатных функций с группировками
Пример 22. Для каждой детали получить суммарное поставляемое количество (ключевое слово GROUP BY…):
SELECT
PD.DNUM,
SUM(PD.VOLUME) AS SM
GROUP BY PD.DNUM;
Этот запрос будет выполняться следующим образом. Сначала строки исходной таблицы будут сгруппированы так, чтобы в каждую группу попали строки с одинаковыми значениями DNUM. Потом внутри каждой группы будет просуммировано поле VOLUME. От каждой группы в результатирующую таблицу будет включена одна строка:
DNUM SM
1 1250
2 450
3 300
В списке отбираемых полей оператора SELECT, содержащего раздел GROUP BY можно включать только агрегатные функции и поля, которые входят в условие группировки. Следующий запрос выдаст синтаксическую ошибку:
SELECT
PD.PNUM,
PD.DNUM,
SUM(PD.VOLUME) AS SM
GROUP BY PD.DNUM;
Причина ошибки в том, что в список отбираемых полей включено поле PNUM, которое не входит в раздел GROUP BY. И действительно, в каждую полученную группу строк может входить несколько строк с различными значениями поля PNUM. Из каждой группы строк будет сформировано по одной итоговой строке. При этом нет однозначного ответа на вопрос, какое значение выбрать для поля PNUM в итоговой строке.
Некоторые диалекты SQL не считают это за ошибку. Запрос будет выполнен, но предсказать, какие значения будут внесены в поле PNUM в результатирующей таблице, невозможно.
Пример 23. Получить номера деталей, суммарное поставляемое количество которых превосходит 400 (ключевое слово HAVING…):
Условие, что суммарное поставляемое количество должно быть больше 400 не может быть сформулировано в разделе WHERE, т.к. в этом разделе нельзя использовать агрегатные функции. Условия, использующие агрегатные функции должны быть размещены в специальном разделе HAVING:
SELECT
PD.DNUM,
SUM(PD.VOLUME) AS SM
GROUP BY PD.DNUM
HAVING SUM(PD.VOLUME) 400;
В результате получим следующую таблицу:
DNUM SM
1 1250
2 450
В одном запросе могут встретиться как условия отбора строк в разделе WHERE, так и условия отбора групп в разделе HAVING. Условия отбора групп нельзя перенести из раздела HAVING в раздел WHERE. Аналогично и условия отбора строк нельзя перенести из раздела WHERE в раздел HAVING, за исключением условий, включающих поля из списка группировки GROUP BY.
Использование подзапросов
Очень удобным средством, позволяющим формулировать запросы более понятным образом, является возможность использования подзапросов, вложенных в основной запрос.
Пример 24. Получить список поставщиков, статус которых меньше максимального статуса в таблице поставщиков (сравнение с подзапросом):
SELECT *
FROM P
WHERE P.STATYS
(SELECT MAX(P.STATUS)
FROM P);
Т.к. поле P.STATUS сравнивается с результатом подзапроса, то подзапрос должен быть сформулирован так, чтобы возвращать таблицу, состоящую ровно из одной строки и одной колонки.
Результат выполнения запроса будет эквивалентен результату следующей последовательности действий:
Выполнить один раз вложенный подзапрос и получить максимальное значение статуса.
Просканировать таблицу поставщиков P, каждый раз сравнивая значение статуса поставщика с результатом подзапроса, и отобрать только те строки, в которых статус меньше максимального.
Пример 25. Использование предиката IN. Получить список поставщиков, поставляющих деталь номер 2:
SELECT *
FROM P
WHERE P.PNUM IN
(SELECT DISTINCT PD.PNUM
FROM PD
WHERE PD.DNUM = 2);
Замечание. В данном случае вложенный подзапрос может возвращать таблицу, содержащую несколько строк.
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий:
Выполнить один раз вложенный подзапрос и получить список номеров поставщиков, поставляющих деталь номер 2.
Просканировать таблицу поставщиков P, каждый раз проверяя, содержится ли номер поставщика в результате подзапроса.
Пример 26. Использование предиката EXIST. Получить список поставщиков, поставляющих деталь номер 2:
SELECT *
FROM P
WHERE EXIST
(SELECT *
FROM PD
WHERE
PD.PNUM = P.PNUM AND
PD.DNUM = 2);
Результат выполнения запроса будет эквивалентен результату следующей последовательности действий:
Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P.
В результат запроса включить только те строки из таблицы поставщиков, для которых вложенный подзапрос вернул непустое множество строк.
В отличие от двух предыдущих примеров, вложенный подзапрос содержит параметр (внешнюю ссылку), передаваемый из основного запроса - номер поставщика P.PNUM. Такие подзапросы называются коррелируемыми (correlated). Внешняя ссылка может принимать различные значения для каждой строки-кандидата, оцениваемого с помощью подзапроса, поэтому подзапрос должен выполняться заново для каждой строки, отбираемой в основном запросе. Такие подзапросы характерны для предиката EXIST, но могут быть использованы и в других подзапросах.
Может показаться, что запросы, содержащие коррелируемые подзапросы будут выполняться медленнее, чем запросы с некоррелируемыми подзапросами. На самом деле это не так, т.к. то, как пользователь, сформулировал запрос, не определяет, как этот запрос будет выполняться. Язык SQL является непроцедурным, а декларативным. Это значит, что пользователь, формулирующий запрос, просто описывает, каким должен быть результат запроса, а как этот результат будет получен - за это отвечает сама СУБД.
Пример 27. Использование предиката NOT EXIST. Получить список поставщиков, не поставляющих деталь номер 2:
SELECT *
FROM P
WHERE NOT EXIST
(SELECT *
FROM PD
WHERE
PD.PNUM = P.PNUM AND
PD.DNUM = 2);
Также как и в предыдущем примере, здесь используется коррелируемый подзапрос. Отличие в том, что в основном запросе будут отобраны те строки из таблицы поставщиков, для которых вложенный подзапрос не выдаст ни одной строки.
Пример 28. Получить имена поставщиков, поставляющих все детали:
SELECT DISTINCT PNAME
FROM P
WHERE NOT EXIST
(SELECT *
FROM D
WHERE NOT EXIST
(SELECT *
FROM PD
WHERE
PD.DNUM = D.DNUM AND
PD.PNUM = P.PNUM));
Данный запрос содержит два вложенных подзапроса и реализует реляционную операцию деления отношений.
Самый внутренний подзапрос параметризован двумя параметрами (D.DNUM, P.PNUM) и имеет следующий смысл: отобрать все строки, содержащие данные о поставках поставщика с номером PNUM детали с номером DNUM. Отрицание NOT EXIST говорит о том, что данный поставщик не поставляет данную деталь. Внешний к нему подзапрос, сам являющийся вложенным и параметризованным параметром P.PNUM, имеет смысл: отобрать список деталей, которые не поставляются поставщиком PNUM. Отрицание NOT EXIST говорит о том, что для поставщика с номером PNUM не должно быть деталей, которые не поставлялись бы этим поставщиком. Это в точности означает, что во внешнем запросе отбираются только поставщики, поставляющие все детали.
Использование объединения, пересечения и разности
Пример 29. Получить имена поставщиков, имеющих статус, больший 3 или поставляющих хотя бы одну деталь номер 2 (объединение двух подзапросов - ключевое слово UNION):
SELECT P.PNAME
FROM P
WHERE P.STATUS 3
UNION
SELECT P.PNAME
FROM P, PD
WHERE P.PNUM = PD.PNUM AND
PD.DNUM = 2;
Результатирующие таблицы объединяемых запросов должны быть совместимы, т.е. иметь одинаковое количество столбцов и одинаковые типы столбцов в порядке их перечисления. Не требуется, чтобы объединяемые таблицы имели бы одинаковые имена колонок. Это отличает операцию объединения запросов в SQL от операции объединения в реляционной алгебре. Наименования колонок в результатирующем запросе будут автоматически взяты из результата первого запроса в объединении.
Пример 30. Получить имена поставщиков, имеющих статус, больший 3 и одновременно поставляющих хотя бы одну деталь номер 2 (пересечение двух подзапросов - ключевое слово INTERSECT):
SELECT P.PNAME
FROM P
WHERE P.STATUS 3
INTERSECT
SELECT P.PNAME
FROM P, PD
WHERE P.PNUM = PD.PNUM AND
PD.DNUM = 2;
Пример 31. Получить имена поставщиков, имеющих статус, больший 3, за исключением тех, кто поставляет хотя бы одну деталь номер 2 (разность двух подзапросов - ключевое слово EXCEPT):
SELECT P.PNAME
FROM P
WHERE P.STATUS 3
EXCEPT
SELECT P.PNAME
FROM P, PD
WHERE P.PNUM = PD.PNUM AND
PD.DNUM = 2;
Порядок выполнения оператора SELECT
Для того чтобы понять, как получается результат выполнения оператора SELECT, рассмотрим концептуальную схему его выполнения. Эта схема является именно концептуальной, т.к. гарантируется, что результат будет таким, как если бы он выполнялся шаг за шагом в соответствии с этой схемой. На самом деле, реально результат получается более изощренными алгоритмами, которыми "владеет" конкретная СУБД.
Стадия 1. Выполнение одиночного оператора SELECT
Если в операторе присутствуют ключевые слова UNION, EXCEPT и INTERSECT, то запрос разбивается на несколько независимых запросов, каждый из которых выполняется отдельно:
Шаг 1 (FROM). Вычисляется прямое декартовое произведение всех таблиц, указанных в обязательном разделе FROM. В результате шага 1 получаем таблицу A.
Шаг 2 (WHERE). Если в операторе SELECT присутствует раздел WHERE, то сканируется таблица A, полученная при выполнении шага 1. При этом для каждой строки из таблицы A вычисляется условное выражение, приведенное в разделе WHERE. Только те строки, для которых условное выражение возвращает значение TRUE, включаются в результат. Если раздел WHERE опущен, то сразу переходим к шагу 3. Если в условном выражении участвуют вложенные подзапросы, то они вычисляются в соответствии с данной концептуальной схемой. В результате шага 2 получаем таблицу B.
Шаг 3 (GROUP BY). Если в операторе SELECT присутствует раздел GROUP BY, то строки таблицы B, полученной на втором шаге, группируются в соответствии со списком группировки, приведенным в разделе GROUP BY. Если раздел GROUP BY опущен, то сразу переходим к шагу 4. В результате шага 3 получаем таблицу С.
Шаг 4 (HAVING). Если в операторе SELECT присутствует раздел HAVING, то группы, не удовлетворяющие условному выражению, приведенному в разделе HAVING, исключаются. Если раздел HAVING опущен, то сразу переходим к шагу 5. В результате шага 4 получаем таблицу D.
Шаг 5 (SELECT). Каждая группа, полученная на шаге 4, генерирует одну строку результата следующим образом. Вычисляются все скалярные выражения, указанные в разделе SELECT. По правилам использования раздела GROUP BY, такие скалярные выражения должны быть одинаковыми для всех строк внутри каждой группы. Для каждой группы вычисляются значения агрегатных функций, приведенных в разделе SELECT. Если раздел GROUP BY отсутствовал, но в разделе SELECT есть агрегатные функции, то считается, что имеется всего одна группа. Если нет ни раздела GROUP BY, ни агрегатных функций, то считается, что имеется столько групп, сколько строк отобрано к данному моменту. В результате шага 5 получаем таблицу E, содержащую столько колонок, сколько элементов приведено в разделе SELECT и столько строк, сколько отобрано групп.
Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECT
Если в операторе SELECT присутствовали ключевые слова UNION, EXCEPT и INTERSECT, то таблицы, полученные в результате выполнения 1-й стадии, объединяются, вычитаются или пересекаются.
Стадия 3. Упорядочение результата
Если в операторе SELECT присутствует раздел ORDER BY, то строки полученной на предыдущих шагах таблицы упорядочиваются в соответствии со списком упорядочения, приведенном в разделе ORDER BY.
Как на самом деле выполняется оператор SELECT
Если внимательно рассмотреть приведенный выше концептуальный алгоритм вычисления результата оператора SELECT, то сразу понятно, что выполнять его непосредственно в таком виде чрезвычайно накладно. Даже на самом первом шаге, когда вычисляется декартово произведение таблиц, приведенных в разделе FROM, может получиться таблица огромных размеров, причем практически большинство строк и колонок из нее будет отброшено на следующих шагах.
На самом деле в РСУБД имеется оптимизатор, функцией которого является нахождение такого оптимального алгоритма выполнения запроса, который гарантирует получение правильного результата.
Схематично работу оптимизатора можно представить в виде последовательности нескольких шагов:
Шаг 1 (Синтаксический анализ). Поступивший запрос подвергается синтаксическому анализу. На этом шаге определяется, правильно ли вообще (с точки зрения синтаксиса SQL) сформулирован запрос. В ходе синтаксического анализа вырабатывается некоторое внутренне представление запроса, используемое на последующих шагах.
Шаг 2 (Преобразование в каноническую форму). Запрос во внутреннем представлении подвергается преобразованию в некоторую каноническую форму. При преобразовании к канонической форме используются как синтаксические, так и семантические преобразования. Синтаксические преобразования (например, приведения логических выражений к конъюнктивной или дизъюнктивной нормальной форме, замена выражений "x AND NOT x" на "FALSE", и т.п.) позволяют получить новое внутренне представление запроса, синтаксически эквивалентное исходному, но стандартное в некотором смысле. Семантические преобразования используют дополнительные знания, которыми владеет система, например, ограничения целостности. В результате семантических преобразований получается запрос, синтаксически не эквивалентный исходному, но дающий тот же самый результат.
Шаг 3 (Генерация планов выполнения запроса и выбор оптимального плана). На этом шаге оптимизатор генерирует множество возможных планов выполнения запроса. Каждый план строится как комбинация низкоуровневых процедур доступа к данным из таблиц, методам соединения таблиц. Из всех сгенерированных планов выбирается план, обладающий минимальной стоимостью. При этом анализируются данные о наличии индексов у таблиц, статистических данных о распределении значений в таблицах, и т.п. Стоимость плана это, как правило, сумма стоимостей выполнения отдельных низкоуровневых процедур, которые используются для его выполнения. В стоимость выполнения отдельной процедуры могут входить оценки количества обращений к дискам, степень загруженности процессора и другие параметры.
Шаг 4. (Выполнение плана запроса). На этом шаге план, выбранный на предыдущем шаге, передается на реальное выполнение.
Во многом качество конкретной СУБД определяется качеством ее оптимизатора. Хороший оптимизатор может повысить скорость выполнения запроса на несколько порядков. Качество оптимизатора определяется тем, какие методы преобразований он может использовать, какой статистической и иной информацией о таблицах он располагает, какие методы для оценки стоимости выполнения плана он знает.
 Получите свидетельство
Получите свидетельство Вход
Вход











 Материал по информатике "Язык запросов SQL" (0.13 MB)
Материал по информатике "Язык запросов SQL" (0.13 MB)
 0
0 1693
1693 35
35 Нравится
0
Нравится
0


