 Получите свидетельство
Получите свидетельство Вход
Вход

Цель урока: освоение способов построения по экспериментальным данным регрессионной модели и тренда средствами программы Microsoft Excel. Освоение приемов прогнозирования количественных характеристик системы по регрессионной модели путем восстановления значений и экстраполяции.
Используемые программные средства: табличный процессор Microsoft Excel.
План урока.
1. Организационная часть (5 мин.):
- отметить отсутствующих;
- тип урока (комбинированного типа);
- тема урока;
- цель урока.
2. Устный опрос по предыдущей теме (5 мин.):
- Какие Вам известны формы представления зависимостей между величинами?
- Что такое математическая модель?
- Что такое статистика?
- Что такое регрессионная модель?
- Для чего используется метод наименьших квадратов?
- Что такое тренд?
- В чем смысл параметра R2? Какие значения он принимает?
3. Теоретическая часть. Объяснение нового материала (5 мин.).
4. Задание на лабораторную работу (5 мин.):
- задание на лабораторную работу дано на Рабочем листе (Приложение1);
- 1-е задание на тему “Заболеваемость астмой” выполняется по пунктам 1-7 Рабочего листа;
- заполняется Отчет по лабораторной работе (Приложение2);
- 2-е задание по данной таблице также выполняется по пунктам 1-7 Рабочего листа;
- заполняется Отчет по лабораторной работе.
5. Практическая часть (20 мин.).
Выполнение лабораторной работы.
6. Домашнее задание (5 мин.):
Конспект (тема “Прогнозирование по регрессионной модели”); заполнить лист Отчета полностью (ответить на вопросы).
7. Подведение итогов.
Данный урок по типу относится к уроку комплексного применения знаний, умений, навыков.
Урок нацелен на выработку умения самостоятельно применять полученные знания.
В начале урока идет повторение предыдущего материала, затем объяснение нового материала и закрепление теоретического материала – выполнение лабораторной работы.
Выбор данной темы связан с тем, что практически все люди занимаются планированием на самых разных уровнях: от государственного до домашнего. Практически всегда планирование связано с расчетами.
Теоретический материал к уроку
В управлении и планировании существует целый ряд типовых задач, которые можно переложить на плечи компьютера. Пользователь таких программных средств может даже и не знать глубоко математику, стоящую за применяемым аппаратом. Он должен представлять лишь суть решаемой проблемы, готовить и вводить в компьютер исходные данные, интерпретировать полученные результаты. Программным продуктом, который можно использовать для этих целей, является Microsoft Excel.
Microsoft Excel – это не просто электронная таблица с данными и формулами для вычислений. Это универсальная система обработки данных, которая может использоваться для анализа и представления данных в наглядной форме.
Одной из чаще всего используемых возможностей Microsoft Excel является экстраполяция данных – например, для анализа имеющихся фактических данных, оценки тенденции их изменения и получения на этой основе краткосрочного прогноза на будущее. В этом случае используется линейная экстраполяция данных на основе наименьшего квадратичного отклонения – отыскивается линейная зависимость данных, такая, которая бы минимизировала сумму квадратов разностей между имеющимися фактическими данными и соответствующими значениями на прямой линейного тренда (интерполяционной или экстраполяционной зависимости). На основе найденной зависимости можно сделать разумное предположение об ожидаемых будущих значениях изучаемого ряда данных.
Решение задач планирования и управления постоянно требует учета зависимостей одних факторов от других. Например:
1)время падения тела на землю зависит от первоначальной высоты;
2)давление зависит от температуры газа в баллоне;
3)частота заболеваний жителей бронхиальной астмой зависит от качества городского воздуха.
Рассмотрим различные методы представления зависимостей.
Если зависимость между величинами удаётся представить в математической форме, то имеем математическую модель.
Математическая модель – это совокупность количественных характеристик некоторого объекта (процесса) и связей между ними, представленных на языке математики.
Математические модели могут быть представлены в виде формул, уравнений или систем уравнений. Рассмотрим примеры других способов представления зависимостей между величинами: табличного и графического. Представьте себе, что мы решили проверить закон свободного падения тела экспериментальным путем. Эксперимент организовали следующим образом: бросаем стальной шарик с балкона 2-го этажа, 3-го этажа (и так далее) 10-ти этажного дома, замеряя высоту начального положения шарика и время падения. По результатам эксперимента мы составили таблицу и нарисовали график (рисунок 1).
|
Н (м) |
t (сек) |
|
6 9 12 15 18 21 24 27 30 |
1,1 1,4 1,6 1,7 1,9 2,1 2,2 2,3 2,5 |
Мы рассмотрели три способа отображения зависимости величин: функциональный (формула), табличный и графический. Но математической моделью процесса падения тела на землю можно назвать только формулу, т.к. формула универсальна. Таблица и диаграмма (график) констатируют факты, а математическая модель позволяет прогнозировать, предсказывать путем расчетов.
Рассмотрим способ нахождения зависимости частоты заболеваемости жителей города бронхиальной астмой от качества воздуха. Любому человеку понятно, что такая зависимость существует. Очевидно, что чем хуже воздух, тем больше больных астмой. Но это качественное заключение. Его недостаточно для того, чтобы управлять уровнем загрязненности воздуха. Для управления требуются более конкретные знания. Нужно установить, какие именно примеси сильнее всего влияют на здоровье людей, как связаны концентрация этих примесей в воздухе с числом заболеваний. Такую зависимость можно установить только экспериментальным путем: путем сбора многочисленных данных, их анализа и обобщения.
В таких ситуациях на помощь приходит статистика: наука о сборе, изменении и анализе массовых количественных данных.
Возьмем пример из области медицинской статистики.
Известно, что наиболее сильное влияние на бронхиально-легочные заболевания оказывает угарный газ – оксид углерода.
Поставив цель определить эту зависимость, специалисты по медицинской статистике проводят сбор данных. Они собирают сведения из разных городов о средней концентрации угарного газа в атмосфере и о заболеваемости астмой (число хронических больных на тысячу жителей). Полученные данные можно свести в таблицу, а также представить в виде точечной диаграммы.
Статистические данные всегда являются приближенными, усредненными. Поэтому они носят оценочный характер. Однако, они верно отражают характер зависимости величин. И еще одно важное замечание: для достоверности результатов, полученных путем анализа статистических данных, этих данных должно быть много.
Из полученных данных можно сделать вывод, что при концентрации угарного газа до 3 мг/куб.м его влияние на заболеваемость астмой несильное. С дальнейшим ростом концентрации наступает резкий рост заболеваемости.
Нужно получить формулу, отражающую зависимость числа хронических больных P от концентрации угарного газа С. На языке математики это называется функцией зависимости Р от С: Р(С). Вид такой функции неизвестен, её следует искать методом подбора по экспериментальным данным. Понятно, что график искомой функции должен проходить близко к точкам диаграммы экспериментальных данных. Строить функцию так, чтобы ёе график точно проходил через все данные точки (рисунок 2), не имеет смысла. Во-первых, математический вид такой функции может оказаться слишком сложным. Во-вторых, уже говорилось о том, что экспериментальные значения являются приближенными.
Отсюда следуют основные требования к искомой функции:
- она должна быть достаточно простой для использования её в дальнейших вычислениях;
- график этой функции должен проходить вблизи экспериментальных точек так, чтобы отклонения этих точек от графика были минимальны и равномерны (рисунок 3).
Полученную функцию, график которой приведен на рисунке 3(б), принято называть в статистике регрессионной моделью. Регрессионная модель – это функция, описывающая зависимость между количественными характеристиками сложных систем. Получение регрессионной модели происходит в два этапа:
- подбор вида функции;
- вычисление параметров функции.
Чаще всего выбор производится среди следующих функций:
y=ax+b – линейная функция;
y=ax2+bx+c – квадратичная функция;
y=aln(x)+b – логарифмическая функция;
y=aebx - экспоненциальная функция;
y=axb - степенная функция.
Если Вы выбрали (сознательно или наугад) одну из предлагаемых функций, то следующим шагом нужно подобрать параметры (a,b,c и пр.) так, чтобы функция располагалась как можно ближе к экспериментальным точкам. Для этого подходит метод наименьших квадратов (МНК). Суть его заключается в следующем: искомая функция должна быть построена так, чтобы сумма квадратов отклонений у – координат всех экспериментальных точек от у – координат графика функции была бы минимальной.
Важно понимать следующее: методом наименьших квадратов по данному набору экспериментальных точек можно построить любую функцию. А вот будет ли она нас удовлетворять, это уже другой вопрос – вопрос критерия соответствия. На рисунке 4 изображены 3 функции, построенные методом наименьших квадратов.
Данные рисунки получены с помощью Ms Excel. График регрессионной модели называется трендом (trend – направление, тенденция).
График линейной функции – это прямая. Полученная по методу МНК прямая отражает факт роста заболеваемости от концентрации угарного газа, но по этому графику трудно что – либо сказать о характере этого роста. А вот квадратичный и экспоненциальный тренды – ведут себя очень правдоподобно.
На графиках присутствует ещё одна величина, полученная в результате построения трендов. Она обозначена как R2. В статистике эта величина называется коэффициентом детерминированности. Именно она определяет, насколько удачной получится регрессионная модель. Коэффициент детерминированности всегда заключен в диапазоне от 0 до 1. Если он равен 1, то функция точно проходит через табличные значения, если 0, то выбранный вид регрессионной модели неудачен. Чем R2 ближе к 1, тем удачнее регрессионная модель.
Метод наименьших квадратов используется для вычисления параметров регрессионной модели. Этот метод содержится в математическом арсенале электронных таблиц.
Получив регрессионную математическую модель мы можем прогнозировать процесс путем вычислений. Теперь можно оценить уровень заболеваемости астмой не только для тех значений концентрации угарного газа, которые были получены путем измерений, но и для других значений. Это очень важно с практической точки зрения. Например, если в городе планируется построить завод, который будет выбрасывать в атмосфере угарный газ, то, рассчитав возможную концентрацию газа, можно предсказать, как это отразится на заболеваемости астмой жителей города.
Существуют два способа прогнозов по регрессионной модели. Если прогноз производится в пределах экспериментальных значений независимой переменной (в нашем случае это значение концентрации угарного газа – С), то это называется восстановлением значения.
Прогнозирование за пределами экспериментальных данных называется экстраполяцией.
Имея регрессионную модель, легко прогнозировать, производя расчеты с помощью электронной таблицы.
Табличный процессор дает возможность производить экстраполяцию графическим способом, продолжая тренд за пределы экспериментальных данных. Как это выглядит при использовании квадратичного тренда для С=7 показано на рисунке 5.
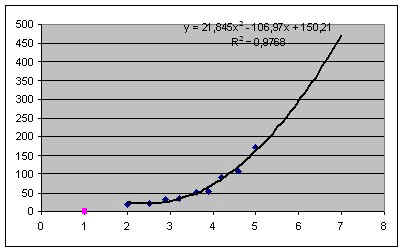
В ряде случаев с экстраполяцией надо быть осторожным. Применимость всякой регрессионной модели ограничена, особенно за пределами экспериментальной области. В нашем примере при экстраполяции не следует далеко уходить от величины 5 мг/куб.м. Вполне возможно, что далее характер зависимости существенно меняется. Слишком сложной является система “экология – здоровье человека”, в ней много различных факторов, которые связаны друг с другом. Полученная регрессионная функция является всего лишь моделью, экспериментально подтвержденной в диапазоне концентраций от 2 до 5 мг/куб.м. Что будет вдали от этой области, мы не знаем. Всякая экстраполяция держится на гипотезе: “предположим, что за пределами экспериментальной области закономерность сохраняется”.
Квадратичная модель в данном примере в области малых значений концентрации, близких к 0,вообще не годится. Экстраполируя её на С=0 мг/куб.м, получим 150 человек больных, то есть больше, чем при 5 мг/куб.м. Очевидно, это нелепость. В области малых значений С лучше работает экспоненциальная модель. Кстати, это довольно типичная ситуация: разным областям данных могут лучше соответствовать разные модели.

















 Регрессионные модели. Прогнозирование по регрессионным моделям (0.17 MB)
Регрессионные модели. Прогнозирование по регрессионным моделям (0.17 MB)
 1
1 3006
3006 65
65 Нравится
0
Нравится
0


